-
DEVIEW 2019|Day 1 세션 후기 - 손글씨 & 스타일변환Events 2019. 11. 10. 00:43
#DEVIEW#DEVIEW2019#NAVER#네이버#데뷰데뷰2019#개발자컨퍼런스#인공지능#AI#머신러닝#ML#딥러닝네이버의 국내 최대 개발자 컨퍼런스, DEVIEW 2019

지난 10월 28일과 29일 이틀동안, 네이버가 국내 최대라고 불리는 개발자 컨퍼런스 DEVIEW2019를 열었습니다! 🎊🎉
제 개인적으로는 개발과 인공지능 분야에 관심을 가지게 된 후로 꼭 가보겠다고 다짐한 컨퍼런스 중 하나였어서, 행사를 진행한다는 소식을 듣자마자 티켓팅 날짜도 확인해가며 기다렸는데요!! ٩(๑˃̶͈ ᗨ ˂̶͈)۶ 두근두근....
하지만 티켓팅은 생각보다도 더 치열했고... 정말 10초 내로 신청을 완료했다고 생각했는데, 신청 버튼을 클릭하자마자 바로.. 마감되었다는.. 화면이 뜨더랍니다... 말이 됩니까.....? 광광 (여러분 데뷰 신청할 때 로그인 꼭 미리 해두세요 ㅠㅠㅠㅠ 안한 바보 ✋🏼접니다..)
좌절하고 있던 찰나에, 함께 티켓팅을 한 친구가 성공을 해서!!! 제가 꼭 가고싶은 이유를 어필해가며 티켓을 양도받는 데에 성공했습니다.. 👍🏼
(뺏은 건 아니구요,, 친구는 Day 1보다 Day 2에 더 관심이 있다고 해서 쿨하게 양도해줬어요!!! 고마워 ㅎㅈ아ㅎㅎㅎㅎ 🧚🏼♀️)
이러한 비하인드 스토리를 통해 결국 갈 수 있게 되어서! (감격) 전날 너무 설레는 마음에 밤잠도 설쳐가며,,ㅋㅋㅋㅋㅋㅋㅋ
무사히 Day 1을 잘 구경하고 왔습니다! 개인적으로는 청록-하늘색의 그라데이션으로 꾸며진 이번 데뷰 색감이 너무 좋았네요. 팔찌도 이쁘고!
Day 1은 AI/ML 세션 중심이었고, Day 2는 클라우드와 플랫폼 등의 엔지니어링 쪽에 조금 더 초점이 맞춰져 있었습니다. Day 2가 다루는 분야는 제가 아직 잘 알지 못해서, 조금 더 집중해서 들을 수 있는 Day 1만 다녀왔습니다. 나중에는 그쪽 분야도 잘 알아서 둘 다 가보고 싶네요 (੭•̀ᴗ•̀)੭
그럼 본격적인 세션 후기로 들어가기 전에, 이번 DEVIEW의 키노트와 세션을 들으며 개인적으로 느꼈던 전체적 감상에 대해 적은 것을 살펴보겠습니다.
저는 아직 인공지능 분야에서 전문가라고 할 수 없는 새싹인데요! (۶•̀ᴗ•́)۶
이런 새싹의 입장에서, DEVIEW에 참가해 느낄 수 있었던 2019년 현재 우리나라 인공지능의 방향성을 한 번 정리해 보았습니다.
앞으로는 어떤 방향으로 흘러갈지, 그리고 어떻게 더 깊어질지에 대해서도 고민해볼 수 있었던 시간이었어요. 한 번 확인해 보시죠!
전문가가 아닌 내가 느낀 2019 인공지능의 흐름
- 현재 다뤄지는 모델들의 거의 대부분을 딥러닝이 차지하고 있고, 주로 논의되는 문제들은 딥러닝 모델의 성능 개선과 더 심화된 기술들이다. 머신러닝은 거의 논외. 아마 컴퓨팅 파워가 워낙 좋아졌기 때문에 굳이 딥러닝 모델을 피해야 할 필요성이 적어져서 인듯 하다.
- 딥러닝은 무르익어가는 단계에 있다. 딥러닝 모델 또는 딥러닝 프로젝트에 대해 소개할 때 더이상 딥러닝 전반에 대한 Intro에 대해서는 언급하지 않고, 더 강화된, 더 응용된 심화 내용들을 바로 시작한다. 그 분위기가 자연스럽다는 것은, 청중들도 딥러닝에 대한 기초 이론에 이미 익숙해져있다는 뜻이다.
- 프로젝트 종류를 불문하고 여기저기에서 많이 언급되는 응용 딥러닝 기술에는 GAN, Transfer Learning, Style transfer 등이 있다. 비교적 단순한 문제인 분류나 예측 등을 넘어서서, 데이터를 생성하거나 변환하는 이런 기술들도 연구단계에서 한창 떠오르는 시즌은 이미 지나갔고, 이제는 괄목할 만한 성과들을 보여주고 있는 단계다. 엄청난 결과물들이 나오고 있다.
- 2019 현재, 자연어는 BERT로 시작해서 BERT로 끝난다. 간혹 BERT 모델의 무거움과 그로 인한 비싼 비용에 대해 이야기하기는 하지만, 그럼에도 아직까지 가장 강력하고 그만큼 실제로도 많이 쓰이고 있다. 아마 BERT를 능가하는 모델이 나올 때까지는 이 강세가 이어질 듯 하다.
- 딥러닝에 대한 연구가 무르익어가면서, 이제 막 떠오르는 트렌드로는 모델 서빙이 있다. 지금까지 개발된 인공지능 모델을 실제로 서비스하기 위한 실질적인 부분들이 많이 고민되고 있다. 특히 모바일에서 서비스될 수 있는 더 가볍고 더 빠른 모델을 만드는 것, 그리고 모델의 즉각적인 서비스화를 위한 자동화된 파이프라인 구축 등에 대한 연구가 활발하다.
- 이와 동시에, 비즈니스 단에서는 모델 서빙에 쓰이는 연산 비용을 줄이기 위한 고민이 함께 이루어지고 있다. 성능과 비용의 트레이드 오프에 대해 고민하고, 그와 함께 가벼운 모델의 성능을 올리는 것에도 노력을 쏟고 있다.
- 그 다음 새로운 트렌드는 자율주행, 강화학습이다. 이 분야가 아직까지는 새로운 트렌드라고 생각한 이유는, 강화학습 세션에서는 아직 '강화학습이란 무엇인지'에 대해 간략히 설명하는 Intro가 있었기 때문이다. 아직 익숙하지 않다는 뜻이다. 하지만 초기 단계인만큼 엄청나게 많은 실험들이 진행되고 있고, 앞으로 아주 큰 성장을 할 것으로 보인다.
- 강화학습, 자율주행 쪽이 떠오르면서 새롭게 주목하게 될 분야는 Robotics이다. 실제로 행사에서 미니치타 로봇을 시연했고, 네이버가 현재 가장 크게 투자하고 있는 1784 프로젝트는 심지어 '로봇 친화적'인 빌딩을 만드는 것이 목표라고 한다. 인공지능 기술이 탑재된 로봇이 더 개발되면서 상용화된다면, 생활에 핵심적으로 사용되는 하드웨어의 변화를 거쳐 우리의 물리적인 생활 양식 자체를 바꿀 것이라고 생각한다.
- 마지막으로 이제 막 '언급이 되기 시작한' 것들에는 Meta Learning, Generalized AI가 있다. 이 분야들은 아직 연구가 핫한 시기에 접어들기도 전으로, 이따금씩 더 심화된 연구로 이것들을 시도해볼 예정이라는 정도로 소개되었다. 이제 점차 보편화된, 일반화된 기계학습 분야가 시작될 것으로 보인다.
간단히 정리해 보면 이렇습니다!
1) 컴퓨터 비전 / 음성 인식 / 자연어 처리 등의 딥러닝 모델은 더 가볍고 빠르게 튜닝해서 실 서비스에 적용되는 사례가 늘어나고 있고,
2) GAN / Style Transfer 등의 응용된 딥러닝 기술 또한 놀라운 성과를 보여주고 있는 단계이며,
3) 자율주행 / 강화학습과 같은 새로운 트렌드는 막 상용화 되려는 단계에 있고,
4) 이제 활발한 연구가 시작된 분야는 Meta Learning, Generalized AI 등이 있다.
(앞서 말씀드렸듯이 위 내용은 전문가가 아닌 입장에서 느껴진 부분들을 주관적인 의견을 담아 정리한 것이므로, 다르다거나 틀렸다고 느끼는 부분이 있을 수 있습니다. 이와 관련해 반대 의견 또는 의문점 등이 있으시다면 언제든 댓글 등으로 피드백 주세요! 더 깊은 논의는 언제나 환영입니다! (੭•̀ᴗ•̀)੭ )
그럼 이제부터 본격적으로 이번 DEVIEW2019에서 직접 듣고 온 내용들을 확인해봅시다!
네이버가 현재 주력하고 있는 산업들을 차례로 소개한 키노트부터, 각 타임 당 하나의 세션들을 골라 총 6개의 세션을 듣고 왔습니다.
제가 들은 세션들과 겹치는 시간대에 꼭 들어보고 싶던 다른 세션들도 많았는데, 하나씩밖에 들을 수 없던 것이 아쉬웠네요. 그만큼 꽤 재미있어 보이던 세션들이 많았으니, 더 많이 보고싶으시다면 한 번 검색해서 확인해보시는 것도 추천드립니다!
(영상 올려준다더니.. 언제 올려주시나요 네이버 ㅠㅡㅠ)
제가 듣고 온 세션 중 제가 가장 흥미롭게 본 두 가지 세션인, 손글씨 세션과 스타일 변환 세션에 대해 알차게 정리해보았습니다.
어떤 부분이 인상적이었는지 한 번 가시 보시죠! 그럼 한 번 출발해볼까요!! ᕕ( ᐛ )ᕗ
Contents
#1. 나 대신 손글씨 써주는 AI 만들기 (성공적인 Side Project)
#2. 신호처리 이론으로 실용적인 스타일 변환 모델 만들기 (Better Faster Stronger Transfer)
#01: 나 대신 손글씨 써주는 AI 만들기 (성공적인 Side Project)
발표자 : 이바도 / NAVER / Clova AI
(아래에 첨부된 모든 이미지의 출처는 이바도님의 발표자료입니다)
가장 인기가 많고 반응이 좋았던 세션이죠!
저 또한 이와 비슷한 손글씨 스타일 변환 프로젝트를 개인적으로 진행했기 때문에 이번 데뷰 중 가장 기대했던 세션이었습니다. 네이버 한글날 공모전에서 보여준 깔끔한 결과물들을 보고, 과연 어떤 기술들을 활용했을까 많이 궁금했었거든요.
예상대로 엄청나게 다양한 최신 기술들을 활용했고, 그만큼 많은 실험이 있었던 것 같습니다. 학습 데이터의 품질부터 사전학습모델의 성능, 그리고 결과물에 대한 후처리까지 많은 고민과 노력이 들어간 프로젝트였어요.
세션의 전체 내용을 통해 더 구체적으로 살펴봅시다.
# OCR 팀에서 손글씨 폰트를 만들기로 한 이유
- OCR이란? 텍스트가 있는 이미지를 입력받았을 때 텍스트가 어디 있고, 뭐라고 쓰여있는지 검출하는 기술
- 일반적인 활자체를 학습하는 OCR은 Pre-train & Fine tune 의 두 단계로 이루어짐
- 이 때, Pre-train의 경우 실제 이미지에 글씨가 써있는 Real data로는 학습하기가 어렵고 비용이 많이 들어서, Synthetic data로 사전학습
- Synthetic data란? 폰트 + 배경이미지를 합성한 이미지 데이터로, 굉장히 많은 데이터를 비용없이 얻을 수 있음
- 하지만, OCR로 읽어내려고 하는 목적은 결국 손글씨이기 때문에, 이를 학습하기 위해서는 손글씨 이미지가 필요
- 그러나 손글씨는 너무 다양하고 불규칙적임 → 직접 손글씨 데이터를 만들자! 라는 결론
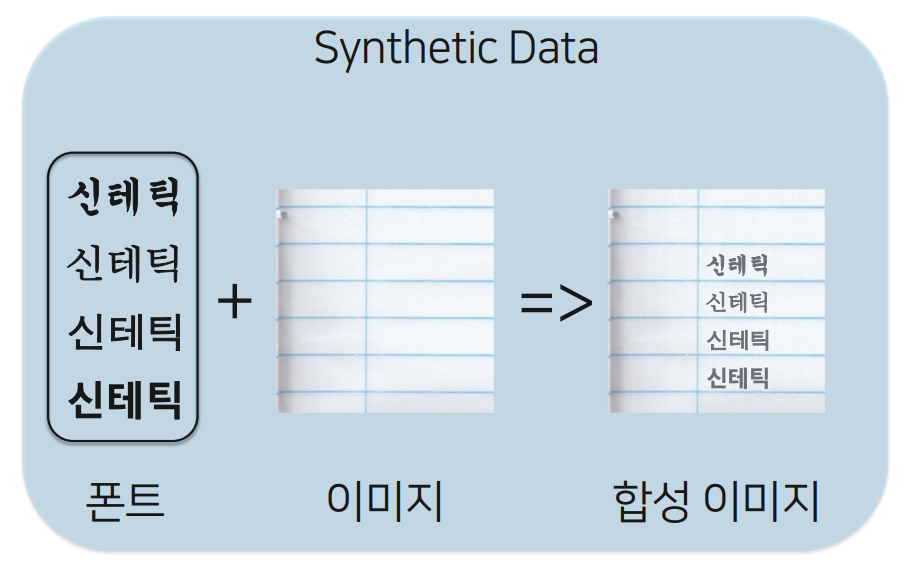
Naver Clova팀이 사용한 Synthetic Data # 하지만, 한글 폰트 만들기의 어려움이란..
- 그래서, 손글씨 폰트를 아예 만들면 어떨까? 하고 시작은 했지만, 한글폰트는 만들기가 너무 어려움. 왜???
- 영어 폰트를 생각해보자. 숫자 10자 + 기호32자 + 알파벳 대소문자 52자 → 총 94자면 완성 가능!
- 하지만, 한글 폰트를 만드려면 몇 자나 필요할까? 완성형 한글 11,172자 + 영어기호 94자 + 낱글자 51자 → 무려 11,317자..
- 일단, 글자가 너무 많다!
- 많은 건 둘째치고, 그렇다면 한글폰트를 만드는 방법은?
- 첫 번째, 조합형 방식 : 각 낱자만 디자인 한 후, 그 글자들을 조합하는 방식
- 하지만, 이런 방식의 경우 각 글자의 자모음 모양이 전부 동일하기 때문에 가독성이 좋지 않고, 이쁘지도 않음
- 일반적인 손글씨의 경우 더더욱 조합형 식으로 사람이 글씨를 쓰지도 않음
- 그렇다면, 두 번째, 완성형 방식은? 각 글자의 디자인을 모두 다르게 하는 것
- 즉, 글자마다 각 자모음의 모양과 위치가 달라지기 때문에 모든 글자들을 하나하나 검수하면서 제작해야 함
- 이건 마치.. 금속활자를 하나하나 파내는 것과 같은 일..
- 즉, 한글 폰트를 생성하기란 아주 어려운 일이다!

한글 폰트를 만드는 두 가지 방식, 조합형과 완성형 # GAN을 많이 쓰던데? 아예 손글씨 폰트를 생성 모델로 생성해보면 어떨까?
- 그래서, 프로토타입으로 빠르게 만들어 봤다!
- 생성 파이프라인
1) Pre-train : 여러 사람의 손글씨 데이터로 미리 학습 (약 3일 소요)
2) Fine-tune : Pre-trained 된 모델을 가지고 원하는 사람의 손글씨로 학습 (약 30분 소요)
3) Generation : 나머지 글자를 모두 생성 (약 5분 이내)

Naver Clova팀이 진행한 손글씨 생성 프로토타입 파이프라인 # 그렇다면, 손글씨 생성 모델은 어떻게 생겼나? : pix2pix
- pix2pix란? Encoder와 Decoder가 조합된 형태의 발전된 GAN 모델

pix2pix 모델의 간단한 구조 # 손글씨 생성의 Proto Type 과 첫 번째 개선
- 글씨가 만들어지기는 하지만, 결과가 아주 좋지는 않음

첫 번째 Proto-Type 생성 결과 - 이유는? Pre-training weight 들이 완전히 최적화되어있지 않고, 데이터셋이 아주 좋은 상태가 아니라고 판단
→ 첫 번째 개선 : Pre-training 에 쓰이는 데이터를 개선해보자!
- 결과는? 여러 글자들의 상태가 깔끔해지며, 많이 개선된 것을 확인

Proto-Type 개선 결과 # 하지만, 여전히 눈에 띄는 문제들
- 글자의 형태를 자세히 확인해보면, 여전히 문제들이 남아있음
- 더 Clear한 글자들을 만들기 위한 개선이 필요

눈에 띄는 문제들의 예 # 손글씨 생성이 유독 어려운 이유, 네 가지
- 스타일이 섞여 있음
- 고려 글꼴 같은 경우, 한글과 영어의 스타일이 아주 다를 수도 있음

어려운 손글씨의 예 - 고려글꼴, 한글과 영어 스타일이 매우 다르다 - 또한, 같은 글자 구조인 알파벳 H와 한글 모음 ㅐ의 경우에도 아주 달라지는 형태가 나타나는 경우도 있음

아주 다른 H와 ㅐ - 두 번째, 사람의 손글씨는 똑같이 절대 못쓴다!
- 사람은 같은 글자를 두 번 쓰더라도 절대 두 번 다시 같게 쓰여지지 않음

같은 사람이 같은 글자를 두 번 썼지만 완전히 동일하지 않음 - 세 번째, 생성모델의 학습이 상당히 불안정한 것도 한 몫!
- Loss 그래프를 본다면, 학습을 어디서 끊어야 할지 감이 안옴
- Loss랑 실제 보이는 퀄리티랑 직접적인 연관이 없어 보이기도 함

불안정한 Loss.. - 네 번째, Labeling 된 손글씨 데이터가 잘 없다!
- 쓰여있는 손글씨는 많지만, label은 많이 되어있지 않음
- 여기서 Labeling이란, 사람의 손글씨가 어떤 글자를 쓴 것인지에 대한 매핑이 안되어 있다는 뜻
# 개선을 해보자! - 1차 성능 개선 : Pre-train 성능 올리기
- 생성된 결과물을 더 좋게 만들기 위해서는, Pre-train부터 잘하자!
- 안정적으로 (틀린 글자 없이), 스타일을 잘 반영 (비슷하게) 하도록 학습시키자
- 개선하기 위해 사용한 기술들 :

Naver Clova팀이 Pre-train을 개선하기 위해 시도한 기술들.. (엄청나다..) # 개선 결과에 대한 검증 & 평가
- 정말 개선되었을까?
- 사람들도 그렇게 생각할까?
- 직원들의 손글씨를 생성해보고 피드백을 해보자 : 90%의 사용자가 만족한다고 응답

개선된 Pre-train 모델로 직접 사람의 손글씨를 생성해 본 결과 (엄청나다....) # 좋은 결과가 나온 후 새로운 도전: 한글날 공모전
- 결과물 품질이 뛰어나게 나오니, 기획팀에서 손글씨 폰트 서비스에 대해서 연락이 옴
- "세 달 남은 한글날을 위해 한글날 공모전을 진행해보자..!" 네이버 입사 후 가장 바빴던 세 달의 시작..
- 실제로 배포될 폰트들을 만드려고 보니 떠오르는 질문들
- 템플릿에 글자를 쓴 후 입력할 때, 스캐너를 꼭 써야 하나요?
- 템플릿에 써야하는 글자가 많고 어려워요
- 혹시 결과물에 대한 추가적인 성능 개선의 여지는 없을까요?
- 사용자는 항상 옳으니.. 성능과 사용성을 개선하기 위해 할 수 있는 것은 다 하자. 할 수 없는 것도 다 하자..! (엄청난 마인드..)
# 실 사용 폰트를 배포하기 위한, 추가 개선 세 가지
- 추가 개선 첫 번째, 전처리 뜯어 고치기!
- 사용자들이 템플릿에 글자를 쓴 후 스캐너를 이용해서 입력하기가 번거롭다는 의견
- 초기 템플릿은 그냥 네모칸으로 이루어져서, 칸의 외곽선을 검출하고 등간격 분할한 후, 이미지를 처리하는 방식
- 등간격 분할을 할 때 글씨의 크기나 위치에 따라 잘려나가는 부분이 있는 등의 문제로 좋은 데이터셋이 만들어지지도 않음
- 해결 : 마커 템플릿 사용! (출처 : OpenCV ArUco)
- 글자 위치 검출용 마커를 템플릿에 넣어서 만드니, 스마트폰으로 편하게 찍거나, 템플릿이 회전되어 있는 상태에서도 데이터 생성이 가능

개선안1: 마커 템플릿 - 추가 개선 두 번째, 템플릿의 글자를 줄이고, 쉬운 글자로 구성하자!
- 처음에는 템플릿에 너무 어려운 글자가 많았음
- 글자 수가 결과물에 어떤 영향을 미치는지 알아보기 위해 템플릿의 글자 수를 400자 ~ 10자 로 줄이면서 실험
- 200자 이하일때는 결과물 품질이 떨어지지만, 200자와 400자는 큰 차이가 없음 → 200자로 줄이자!
- 또한, Template에 쓰이는 글자들을 다양한 조합형 글자를 포함하도록 구성하자
- 조합형 글자를 포함하도록 구성하면 더 많은/어려운 글자를 쓰지 않아도 효과적으로 학습이 가능할 것이라고 판단

조합형 Font Template 아이디어를 통해 템플릿에 있는 글자를 쉽게 개선 - 추가 개선 세 번째, 성능을 좀 더 개선하자!
- 결과물의 성능을 좀 더 끌어올리기 위해, Pre-train 모델이 학습하는 폰트를 손글씨와 비슷한 폰트로 시작하자
- Metric Learning : 고정 시드 글꼴에서 시작하는 게 아니라, 유사 시드 글꼴로부터 시작하자
- 각 폰트들에 대해서 특징 추출을 해서 각 비슷한 글자들을 분류해본 후, 그 결과를 토대로 유사 시드 글꼴을 선택

글자 별로 특징을 추출해 유사도 계산 # 생성된 폰트 결과물에 대한 후처리 세가지
- 첫 번째: Vector Tracing, 더 선명한 글자를 위해
- 확대를 해도 깨지지 않는 Vector 포맷으로의 변환

확대해도 깨지지 않는 Vector 이미지로 후처리 - 각 글자에 대한 사이즈를 정규화 해서 비슷하게 만들어줌
- 영어의 경우, 글자의 위치 또한 같은 라인에 있도록 처리
# 실제 생성이 되는 전체 과정, Production Pipeline
- 지원자들의 손글씨 데이터가 MySQL에 쌓이면, Data collector가 데이터를 전처리
- 전처리가 끝나면 Kafka가 전처리가 완료되었다는 메세지를 전달
- 그 후 GPU 서버에서 Finetune & Generate 등의 과정을 거쳐서 모든 결과물을 생성

Production Pipeline # 성황리에 끝난 한글날 공모전, 그 후.. What's next?
- 생각보다 너무 흥한 한글날 공모전
- 참가 지원을 받았던 20일 동안 약 25,000명 이상이 지원!
- 그렇다면, 이 이후에는 무엇을 할 수 있는가?
- 첫 번째, Few Shot에 대한 도전: 현재는 약 200자를 템플릿으로 활용해서 손글씨 생성
- 앞으로 더 개선된 성능을 이용하면 10자만으로 손글씨 폰트를 생성할 수 있지 않을까.. (엄청나다.....)
- 두 번째, Template-less도 시도 가능: 템플릿 없이, 이미 쓰여있는 글자만으로 생성하기
- 이건 사실 이미 시도해서 성공은 함..

Template를 사용하지 않고, 왼쪽의 이미지만으로 폰트를 생성한 결과물 - 앞으로 이런 방식을 더 개선시켜서 훨씬 많은 손글씨 폰트를 생성할 수 있을 것으로 기대
- 이렇게 손글씨 폰트 생성을 통해 OCR 또한 훨씬 개선될 것
첫 번째 세션은 여기까지 입니다!
개인적으로는 눈에 보이는 결과물들이 있어서 더 재미있게 들을 수 있었습니다. 중간에 성능 개선을 위해 여러 기술을 시도해 본 부분을 발표 상으로는 빠르게 나열하며 지나갔지만, 사실 그 부분에서 가장 많은 노력이 들어갔다는 것도 알 수 있었죠!
결과물은 말할 것도 없이 엄청났구요..!
앞으로 10글자만으로 사람의 손글씨를 모두 반영한 폰트 생성 기술을 개발할 예정이라는데, 기대해봐도 좋을 것 같습니다.
그럼 바로, 두 번째 세션으로 가보겠습니다!
#02: 신호처리 이론으로 실용적인 스타일 변환 모델 만들기 (Better Faster Stronger Transfer)
발표자 : 유재준 / NAVER / Clova AI
(아래에 첨부된 모든 이미지의 출처는 유재준님의 발표자료입니다)
두 번째 세션 또한 매우 흥미로웠습니다. 스타일 변환이라는 기술은 위에 보았던 손글씨 세션이랑도 연결되는 부분이 있죠.
사실 스타일 변환이라고 하면 딥러닝을 공부하는 사람들은 고흐의 별이 빛나는 밤 등의 명화 작품으로 변환된 이미지들을 많이 떠올릴 것 같습니다.
저 또한 그 결과물을 보고서 스타일 변환에 관심이 크게 생겼었는데요!
이번 세션에서는 더욱 놀라운 결과물들을 보여주었습니다.
실제로 발표하신 유재준님이 속한 네이버의 클로바팀이 WCT2 모델을 개발해서 이번 ICCV 2019 학회에서 발표를 했다고 합니다. (엄청나..)
그럼 바로 확인해보시죠!
# Style Transfer, 스타일 변환이란 뭘까?
- 이미지에서 스타일(style) 은 뭘까? 반대로 컨텐츠(contents) 는 뭐지?
- 딥러닝을 이용한 Style Transfer 기법에서는, 결국 이미지의 스타일과 컨텐츠를 계산이 가능한 정량값으로 표현하는 것이 중요
- 그렇다면, 그 스타일과 컨텐츠를 어떻게 옮길까?
- 스타일과 컨텐츠를 잘 추출해낸 후, 하나의 이미지를 다른 이미지로 어떻게 잘 옮길 것인지도 중요한 문제
- 스타일 변환에는 크게 두 가지가 있다
- 첫 번째, Artistic : 이미지를 예술적인 스타일로 변환하는 문제
- 두 번째, Photorealistic : 이미지를 사실적으로 변환하는 문제

Artistic Style Transfer의 예 - 이미지를 고흐풍 그림으로 변환 
Photorealistic Style Transfer의 예 - 낮에서 밤 또는 밤에서 낮으로 변환 # 그렇다면, Style Transfer가 중요한 이유는?
- 스타일 변환과 관련된 연구들이 아주 다양하기 때문!
- Style Transfer 중 Style과 관련된 연구들
- Unsupervised Learning / Representation Learning / Feature Extraction
- Style Transfer 중 Transfer와 관련된 연구들
- Domain Translation / Domain Adaptation / Domain Augmentation
- Style과 Transfer, 둘 모두와 관련된 연구는? Generative Model!
# 옛날에는 Style Transfer를 어떻게 접근했을까?- 이미지의 질감(Texture)을 생성했음
- 질감이란? 이미지 전반에 걸쳐 색이나 방향, 크기, 위치가 조금씩 바뀌면서 반복되는 간단한 이미지 요소(elememts)
- 1962년, Julesz Conjecture의 주장 : "임의의 질감이 두 개 있을 때, 이 둘의 2nd-order 통계량이 같다면 사람은 이 둘을 구별하지 못한다"
- Béla Julesz가 제안한 Texton의 개념 : "인간이 어떤 선형 필터들의 조합으로 표현되는 질감을 인지하는 최소 단위"
- 여기서, 선형 필터들의 조합이란? 선형 관계인 weight들로 연산될 수 있는 것들
- 이러한 접근의 문제점은, 각각의 질감마다 선형 필터를 직접 수학적인 연산을 통해 정의해야 했음 : 수작업 ↑
# 이러한 문제를 해결하게 된, CNN의 등장
- 이 문제를 최초로 해결한 접근 : CNN의 등장 (2015)
- CNN의 등장으로, 이미지의 Style vector를 추출할 수 있게 됨. 어떻게?
- Input 이미지를 픽셀과 픽셀 간의 위치관계만으로 보는 것이 아니라, CNN의 각 계층이 추출하는 Feature들의 상관관계로 정의하기 때문.

CNN을 통해 추출한 각 이미지의 Style (맨 위의 이미지) - 이렇게 CNN의 각 계층에서 뽑아낸 Feature들 간의 상관관계로 질감(=스타일)을 뽑아낸 것을 Gram Matrix라고 함
- 컨텐츠(contents)는 각 layer의 representation으로 사용
- 즉, contents는 픽셀의 위치 정보를 맞추는 역할로 사용하고, style을 유지시키는 것은 분산이 최소화되어야 한다는 제한조건을 통해 학습
- 이게 되는 이유는?
- MMD(Minimizing Maximum Mean Discrepancy) 연구에서, Gram 행렬을 맞추는 것이 2nd-order polynomial kernels를 맞추는 것과 동일하다는 것을 수학적으로 증명
- 여기서 특이한 점은, 많고 많은 좋은 CNN 뉴럴넷 중 VGG만 잘 되는 것으로 확인됨
- 왜? 이유는 아직 명확히 밝혀지지 않음. 우리에게 남은 과제
- CNN의 한 가지 더 남아있는 이슈는: 이미지를 해석하는 과정이 Texture에 편향되어 있는 것으로 보인다는 것!
- 우리에게 주로 잘 알려진 바로는, CNN의 앞단에서는 물체의 Edge를 주로 검출하고, 뒷단에서는 점점 복잡한 구조를 읽는다는 것
- 그래서 지금까지는 texture가 아니라 이미지의 구조를 보고 예측이 이루어지는 것으로 생각함
- 하지만, 직접 확인해보니 textrue에 아주 예민하고, 구조는 조금만 바뀌어도 많이 틀린다는 것을 확인할 수 있다!

CNN이 texture에 예민하다는 증거: 고양이의 형상만 남은 이미지는 정확도가 떨어지지만, 코끼리 피부 질감 이미지는 100%로 맞춤 - 여기서 떠오르는 생각은: CNN은 구조가 아니라 Texture만으로 이미지를 해석하는가?
- 하지만, 그렇다고 texture만을 이용하는 것은 아님. CNN이 이미지를 읽는 방법에 대해서는 계속 연구가 필요함
# 최신 연구 흐름 한눈에 살펴보기 - Artistic Style Transfer
1) Feed forward network : 기존의 Style Transfer 기법.
- 여기서 단점은, 변환하기를 원하는 각각의 스타일마다, 네트워크를 새로 학습시켜야 함
- 그래서 나온 아이디어가, Instance Normalization
2) Instance Normalization (IN) : "스타일 변환 결과가 컨텐츠 이미지의 Contrast에 따라 바뀌지 않게 하자"
- 즉, 이미지 하나하나를 쪼개서 Normalization해서, 그 결과를 scale factor로 사용하자는 아이디어
- 이렇게 정규화된 이미지를 스타일 값으로 shifting & scaling 만 해도 스타일이 먹힌다는 결과 : conditional instance normalization 기법 (CIN)
- 이렇게 하면, 여러 스타일을 한 번에 바꿀 수 있다!
3) Adaptive Instance Normalization (AdaIN) : "Scaling & Shifting 값을 구하는 과정을 아예 학습과 분리하자"
- 먼저 Content를 잘 복원하도록 모델을 학습시킨 후, Contents 이미지와 Style 이미지의 feature를 둘 다 추출
- 추출된 두 feature의 mean과 std를 계산해서, content 이미지에서 scale factor를 뺀 후, 스타일 이미지의 scale factor를 입히는 방식
- 여기까지 오니, Artistic Style Transfer 뿐만 아니라 Photorealistic Style Transfer까지 자연스럽게 되더라

AdaIN의 결과: 사진에서 사진으로의 변환, 즉 Photorealistic 스타일 변환이 자연스러움 - 하지만, 아직 불만족스럽다: 평균과 분산만 맞추지 말고, 공분산까지 맞춰보는 건 어떨지?
4) Whitening and Coloring Transforms (WCT) : 공분산까지 맞추는 모델
- 공분산까지 맞춘다는 것은, 좀 더 Fine tuning이 되도록 하는 것
- Auto Encoder는 똑같이 학습시킨 후, Whitening & Coloring을 진행
- Whitening이란? 이미지의 색을 쫙 빼는 작업, content를 유지하면서 style을 빼는 작업으로 볼 수 있음

whitening 된 이미지 결과 - Coloring이란? 이미지에 색을 다시 입히는 작업, Style을 입히는 것으로 볼 수 있음

왼쪽의 style로 오른쪽의 사진에 Coloring 한 결과 - 하지만.. 여전히 문제는 남아있음: 한 번에는 잘 안먹히기 때문에 recursive하게 여러번 스타일을 먹여주기 때문에,
- 느리고, error는 증폭되고, 모델의 크기 또한 너무 큼
- 또한, Photorealistic 변환에는 쓰일 수 없음
# 최신 연구 흐름 한눈에 살펴보기 - Photorealistic Style Transfer
1) Deep Photo Style Transfer (DPST)
- 이미지의 각 부분을 하나의 모드로 생각해서, 각 모드의 스타일을 유지시켜야 한다는 제한조건 하에서 학습

각 이미지의 성분 부분을 모드로 생각해서 box로 표현 - 하지만, 잘 학습이 안됨..? → 하늘은 하늘끼리, 건물은 건물끼리, 각자의 스타일이 맞도록 따로따로 관리하자는 아이디어
- 즉, 각 성분에 대해 split 해서 문제를 풀기
2) PhotoWCT
- WCT를 Photorealistic 문제를 풀 수 있도록 개선해보자.
- 원래 VGG에서 max pooling을 했던 것을 생각해보면, 그 작업은 엄청나게 많은 정보를 버리는 것으로 볼 수 있음
- Decoder에게 최소한 max pooling을 했던 위치라도 제공을 해주면 도움이 되지 않을까? (Unpooling)
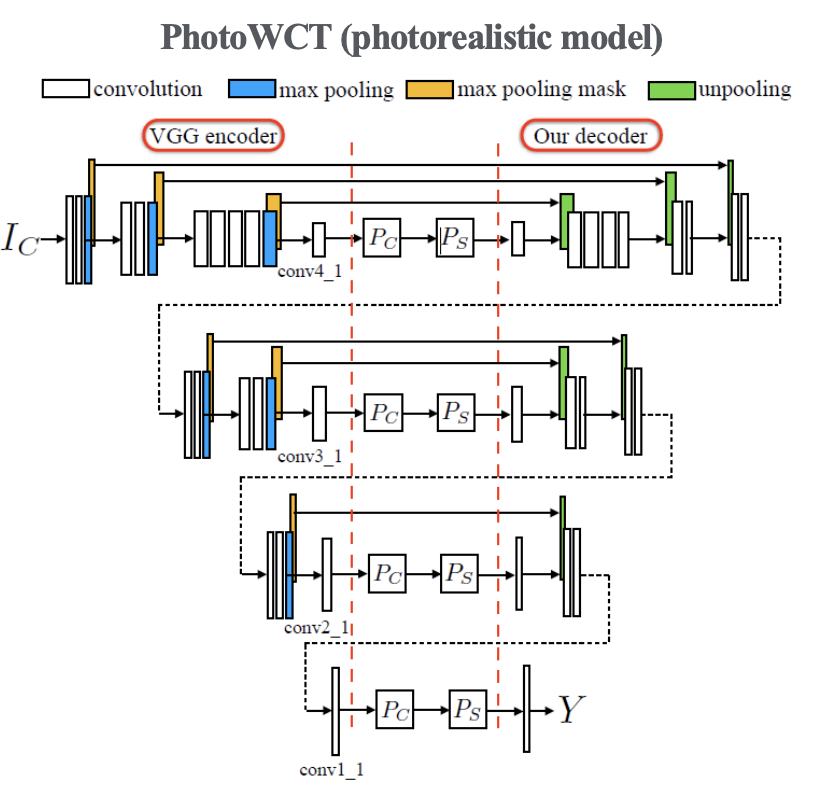
Unpooling을 통해 Decoder에게 정보를 제공해주는 모습 - 그러나, 실제로 시도해보니 unpooling은 생각보다 효과가 없다?

WCT와 비교했을 때 PWCT가 뚜렷하게 뛰어나진 않음 - 여기서, 한 가지 더 개선한 점: Smoothing, 즉 네트워크가 생성한 이미지에 후보정 처리 과정이 결과물 품질을 훨씬 좋게 만듦
- 하지만, 연산량은 훨씬 많아져서 여전히 느리기만 함

가운데의 PWCT + smoothing 결과가 가장 깔끔 - 그래서 Clova가 새로 개발했다! → WCT2
# 그래서, Clova가 후처리 없이도 깔끔하게 만들 수 있는 모델을 개발했다: WCT2!
- Encoder와 Decoder가 좋은 성질을 갖는 함수를 학습할 수 있도록 강제하는 구조를 갖자!
1) Pooling과 비슷한 역할을 하면서,
2) Encoding - Decoding 과정에서 이미지에 대한 정보를 잃지 않아야 하고,
3) 입력 이미지의 특징을 충분히 잘 표현할 수 있는 모듈은?
- 신호처리 이론에서 사용되는 WCT (Wavelet Corrected Transfer) 모듈을 응용
- 원래 사용하던 Pooling 대신, waveling pooling으로 바꾸어서 사용

WCT 모듈의 구조 - 이렇게 했더니, Low frequency 스타일을 입히면 실제로 그렇게 동작하는 것을 확인! → Interpretable 하다는 것!
- 또한 Multi-level 대신, Progressive stylization 으로 한 번의 feed-forward 만 수행
- 즉, 하나의 모델만 사용하기 때문에 error가 전파되는 것을 막아서 깔끔하면서도,
- 더 가볍고 빠른 스타일 변환이 가능

Cherry pick 없이 깔끔한 결과 - 맨 오른쪽의 WCT2 (스타일이 변환되면서도 하늘의 구름을 그대로 보존한 모습.. 충격적) 
Cherry pick 없이 깔끔한 결과2 - 역시 하늘의 구름을 깨끗하게 보존했고, 심지어 샴페인의 기포마저 그대로 남아 있는 모습.. - 아직 충격적인 결과는 끝이 아니다! : 비디오 스타일 변환도 잘 되는 모습!
- WCT2의 스타일 변환은 매우 가볍고 빠르기 때문에, 비디오가 재생됨에 따라 각 프레임에 대해 계속적으로 변환 가능
- 고해상도 이미지에 대해서도 가능!

비디오에 대해서도 스타일 변환이 가능한 모습
여기까지가 두 번째 세션이었네요!
Style Transfer 기법에 관해 평소 매우 흥미로운 실험이라고 생각해서 관심이 많았는데, 이번 Clova 팀이 보여준 성과는 꽤 놀랍습니다.
깔끔한 결과물이 나온 것뿐만 아니라, 모델까지 매우 가벼워지면서 비디오 변환도 빠르게 가능한 결과가 정말 대단하네요.
개인적으로는 신호처리 이론을 접목시켜서 모델을 개선시켜 본 것이 매우 신기했습니다. 딥러닝 분야를 공부하다보면, 직접적으로 딥러닝에 관련된 분야가 아니더라도, 공학, 또는 신경학과 인지심리학 등의 다양한 분야의 도메인 지식을 이용해서 큰 개선을 이루어낸 사례가 종종 있는 것 같아요.
그만큼 다른 영역과의 융합이 가능하고, 잠재력 또한 무궁무진하다는 것으로 보입니다.
여기까지가 제가 보고 온 두 가지 세션을 정리해 보았습니다.
사실 이 외에도 모바일 딥러닝 서빙, 얼굴인식, 강화학습 로봇 에이전트 등 흥미로운 세션들이 있었는데 더 많이 리뷰하지는 못해서 아쉬움이 남네요.
하지만! 네이버가 곧 영상을 올려준다고 하니, 관심 있으신 분들은 영상으로도 함께 만나보시면 좋을 것 같아요!
많은 새로운 것들을 접하며 생각을 넓힐 수 있었던 시간이었습니다. 내년에도 꼭 참석해야겠어요!!! 😆
'Events' 카테고리의 다른 글
[NAVER DEVELOPER OPEN CLASS 2019] 채용설명회 후기 (0) 2019.09.02 댓글