-
내 손글씨를 따라쓰는 인공지능 요정, Wrinie (1) - 이론Side Projects/내 손글씨를 따라쓰는 인공지능 2019. 7. 20. 16:17
#GAN#UNet#Generative Model#CNN#Deep Learning#딥러닝#딥러닝 프로젝트#생성모델#인공지능
본 글은 개인 프로젝트로 진행된 프로젝트에 대한 소개글입니다.
내 손글씨를 따라쓰는 인공지능 요정, Wrinie (1) - 이론 에서는 프로젝트의 큰 그림과 이론적인 내용을,
내 손글씨를 따라쓰는 인공지능 요정, Wrinie (2) - 실습 에서는 프로젝트의 실제 진행 과정에 대한 내용을 담았습니다.
관련 코드는 ↓ 이 곳 ↓ 에서 확인하실 수 있습니다.jeina7/Handwriting_styler
My Handwriting Styler | 내 손글씨를 따라하는 인공지능. Contribute to jeina7/Handwriting_styler development by creating an account on GitHub.
github.com
이 프로젝트는 중국어 글자를 이용해 진행된 zi2zi 프로젝트의 많은 도움을 받았습니다.
모델의 구조, 손실함수 설계 등의 이론적인 부분에서 zi2zi의 내용을 일부 차용하였습니다.
내 손글씨체를 기계가 학습할 수 있을까?
한글은 세계적으로 완성도가 높다고 평가되는 언어 중 하나입니다. 하지만 그렇게 우수한 한글의 유일한 단점은 복잡하다는 것인데, 실생활에 사용되는 상용한글은 2,350자이고, 자모음의 조합으로 만들어낼 수 있는 모든 글자는 총 11,172자에 이를만큼 어마어마한 다양성을 갖고 있기 때문입니다. 대소문자를 모두 합쳐도 52자밖에 안 되는 영어에 비하면 엄청난 양이죠.
이러한 한글의 특성 때문에 한글폰트를 만드는 일은 많은 시간과 비용이 드는 전문적인 작업으로 알려져 있습니다. 전문 디자이너가 작업한다고 해도 완전한 한글 폰트를 만들어내는 데에는 몇 개월 이상의 시간이 걸린다고 합니다.
그렇다면, 인공지능이 내 손글씨를 학습해서 만들어낼 수 있다면 어떨까요?
사람이 몇 글자만 직접 써서 모델에게 주면, 모델이 글씨체의 특징을 파악해서 나머지 글자를 모두 만드는 거죠!
이런 호기심에서 시작된 프로젝트가 바로 내 손글씨를 따라쓰는 인공지능 요정, [Wrinie] 입니다.더 자세한 내용을 알아보기에 앞서, Wrinie가 만들어낸 글자를 먼저 확인해보세요! 어느 쪽이 가짜일까요?

Wrinie의 결과물(1) - 정자체 꽤나 비슷하죠? 똑똑한 Wrinie 😉
각 열에서 오른쪽은 컴퓨터 폰트 그대로의 진짜 이미지이고, 왼쪽이 Wrinie가 생성한 가짜 이미지입니다!언뜻 보기에는 같은 글자들처럼 보이지만, 사실 자세히 보면 디테일들이 조금은 흐린 것들을 확인할 수 있습니다.
그렇다면 손글씨같은 모양의 글씨체들은 어떻게 썼을까요?

Wrinie의 결과물(2) - 필기체 위의 곧은 글씨체들보다는 조금 더 어려워하는 글자들이 있는 것 같습니다. 그래도 이만하면 꽤 잘 따라쓰는 것 같지 않나요??
그러면 이제부터 Wrinie가 어떻게 학습해서 이런 이미지를 만들어내었고, 프로젝트는 어떤 순서로 진행이 되었는지 등, 본격적으로 설명해보도록 하겠습니다.
여러가지 이론과 실험들이 아주 흥미로울 예정이니 집중해주세요! (๑•̀ㅂ•́)و✧
# Contents
1. 내 손글씨를 따라쓰는 인공지능 요정, Wrinie (1) - 이론
1) 프로젝트의 큰 그림
2) 모델의 구조
3) Losses, 여러가지 손실함수2. 내 손글씨를 따라쓰는 인공지능 요정, Wrinie (2) - 실습
4) 데이터셋
5) Pre-Train: 사전학습모델 만들기
6) Interpolation
7) Transfer Learning: 손글씨 학습하기
1. 프로젝트의 큰 그림
사실 말은 거창하게 했지만, 글씨의 특징을 잘 학습해서 비슷한 스타일의 다른 글자들을 생성해낼 수 있도록 모델을 학습시키는 것이 이 프로젝트의 기본적인 목표입니다. 이 목표를 달성하기 위해서 프로젝트는 크게 다음과 같은 두 가지 스텝으로 나뉩니다.
1) First Step [Pre-Training, 사전학습모델 만들기]
모델이 사람의 손글씨를 학습하기 전에 해야 할 일은 글자 이미지 자체를 학습하는 것입니다. 아주 많은 글자 이미지들을 이용해 글자의 특징을 추출하고, 다시 복원하는 방법을 먼저 학습해야 합니다.
따라서 Pre-Training 단계에서는 사람의 손글씨 대신, 대량의 데이터셋을 만들기 쉬운 컴퓨터 폰트 이미지로 학습합니다.

Wrinie가 Pre-Training 할 데이터셋의 샘플 Wrinie는 위 그림과 같이 다양한 스타일의 25가지 폰트 당 랜덤으로 추출된 약 3,000장씩, 총 75,000여 장의 글자 이미지 (128 × 128) 로 학습하였습니다.
Pre-Training 단계의 최종적인 목표는 다음 그림과 같습니다.
고딕체의 글자와 변환하기를 원하는 타겟 폰트 카테고리 정보를 함께 입력받으면, 타겟 폰트가 입혀진 글자를 출력하는 것입니다.
즉, 입력은 고딕체 글자를 받지만, 모델은 폰트가 입혀진 글자로 스타일 변환을 하도록 학습됩니다.
고딕체 글자 + 폰트 카테고리 정보 → 스타일이 변환 된 글자 이렇게 75,000자의 데이터로 제대로 학습이 된다면 모델은 이제 컴퓨터 폰트 글자를 잘 쓸 수 있게 됩니다. 이 모델을 베이스 모델로써 활용해 다음단계에서 사람의 손글씨를 학습할 것입니다.
2) Second Step [Transfer Learning, 손글씨 학습하기]
잘 학습된 사전학습모델이 준비되었다면, 이제 이 모델을 Transfer Learning (전이학습) 시켜서 사람의 손글씨를 학습할 수 있도록 할 것입니다.
Transfer Learning이란, 이미 학습이 되어있는 모델을 다른 데이터셋이나 다른 목적의 프로젝트에 입맛에 맞게 적용시켜 사용하는 것입니다. 사전에 학습되어 있는 모델을 사용하면 처음부터 학습시키지 않아도 되므로 시간과 자원을 절약할 수 있어 유용합니다.
Transfer Learning에 대해 자세히 알고싶다면 제가 이전에 번역한 포스트인 [Transfer Learning | 학습된 모델을 새로운 프로젝트에 적용하기] 를 참고하세요!(다양한 상황별로 Transfer Learning을 어떻게 적용하면 좋은지 친절하게 설명되어 있습니다.)
아무튼, 첫 번째 단계에서 직접 학습시켜놓은 사전학습 모델이 있으니 충분히 활용하면 좋겠죠! 이번 단계의 목표는 컴퓨터 폰트에 대해서는 거의 99% 완벽하게 베껴내는 사전학습 모델을 가지고, 보다 어려운 사람의 손글씨를 학습시키는 것입니다.
따라서 당연히 이번 단계에서 모델이 학습하는 데이터셋은 사람의 손글씨입니다. 하지만 사람의 손글씨는 말그대로 사람이 직접 써야하므로 컴퓨터 폰트만큼 대량으로 만들기 쉽지 않습니다. 또 우리의 목적은 폰트를 만들 때 사람이 직접 작업하는 양을 줄이는 것이기 때문에, 이번 단계에서 모델은 1단계에 비해 아주 적은 양의 데이터셋으로만 학습합니다.Wrinie는 아래와 같이 제가 템플릿 위에 직접 쓴 210자의 글자 데이터만으로 학습되었습니다.

템플릿에 쓰여진 210자 손글씨의 일부
이번 단계의 최종 목표는 적은 데이터만으로 사람의 글씨체의 특징을 효과적으로 학습해서, 나머지 11,172자의 글자까지도 비슷한 글씨체로 생성해내는 것입니다.아래 그림은 제가 직접 쓴 손글씨와 모델이 생성한 글씨를 비교한 것입니다.
어때요, 적은 데이터만으로 학습한 것 치고는 꽤나 제 스타일을 반영해준 것 같지 않나요?
지금까지 설명한 두 가지 학습 단계를 간단하게 정리하자면!
1) 컴퓨터 폰트로 글씨를 먼저 학습하는
Pre-Train단계와,
2) 사람의 손글씨를 학습하는Transfer Learning단계, 로 정리될 수 있을 것 같네요!그럼 프로젝트의 큰 그림에 대해 알아보았으니 이제, 모델의 구조는 어떻게 생겼는지, 그리고 학습은 어떤 방법으로 이루어지는지 알아보러 가보겠습니다!
2. 모델의 구조
모델의 기본적인 구조는 생성모델인 GAN (Generative Adversarial Networks) 입니다.
GAN 이란 이미지 분류기 모델과는 달리 이미지를 직접 생성해내는 모델입니다. 자세하게 읽어보고 싶으신 분은 쉽게 씌어진 GAN을 추천드립니다!Original GAN, 즉 가장 기본적인 GAN 구조를 그림으로 그리면 다음과 같습니다.

위와 같이 GAN은 이미지를 생성해내는 Generator 부분 (파란색) 과, 진짜 이미지인지 가짜 이미지인지 검출해내는 Discrimitor 부분 (빨간색) 으로 구성됩니다.- Discriminator는 이미지를 입력받으면 진짜인지 가짜인지에 대한 예측을 0~1 사이의 값으로 확률값을 출력합니다. 출력된 확률값으로 정답
(True: 1, False: 0)과 비교해서 얼마나 잘 맞췄는지 피드백을 받으면서 점점 똑똑한 검사기가 됩니다. - 반면, Generator는 Discriminator 를 속이는 것이 목표입니다. 처음에는 제대로 된 이미지를 생성하지 못하던 Generator는 Discriminator를 속일 수 있을만큼 점점 더 진짜같아 보이는 이미지 생성해내도록 학습합니다.
이렇게 Discriminator와 Generator가 서로 겨루며 (Adversarial) 학습하는 것이 GAN 학습의 기본 원리입니다.
즉, GAN은 아무 의미가 없는 noise 벡터를 입력으로 받으면, 의미가 있는 이미지를 생성해내는 것이 최종 목표입니다.
하지만, Wrinie의 목표를 다시 떠올려보면 어떤가요?
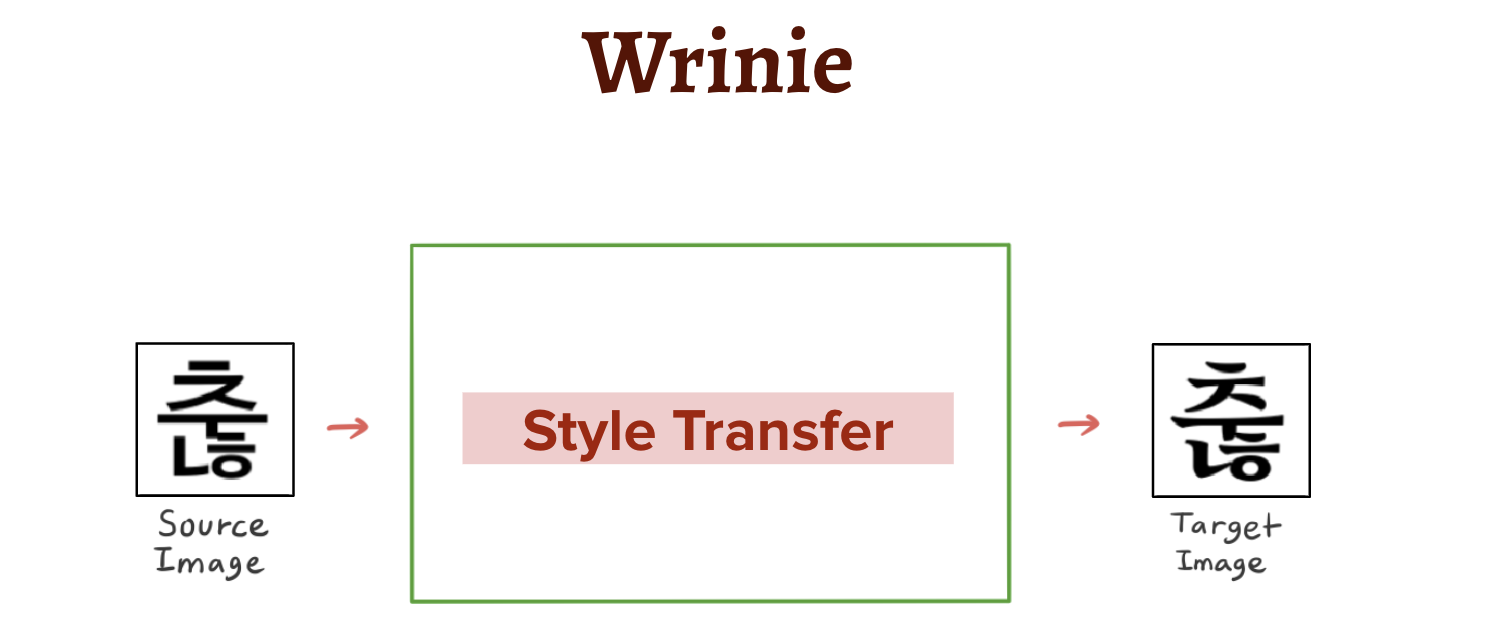
Wrinie의 입력 데이터는 고딕체의 글자이고, 출력해야 하는 데이터는 스타일이 변환된 새로운 글자입니다.
즉, 입력 데이터가 noise인 Original GAN 과는 비슷하면서도 명확하게 다릅니다.따라서 이런 상황에서 Wrinie가 가져야 하는 구조는 다음과 같습니다.
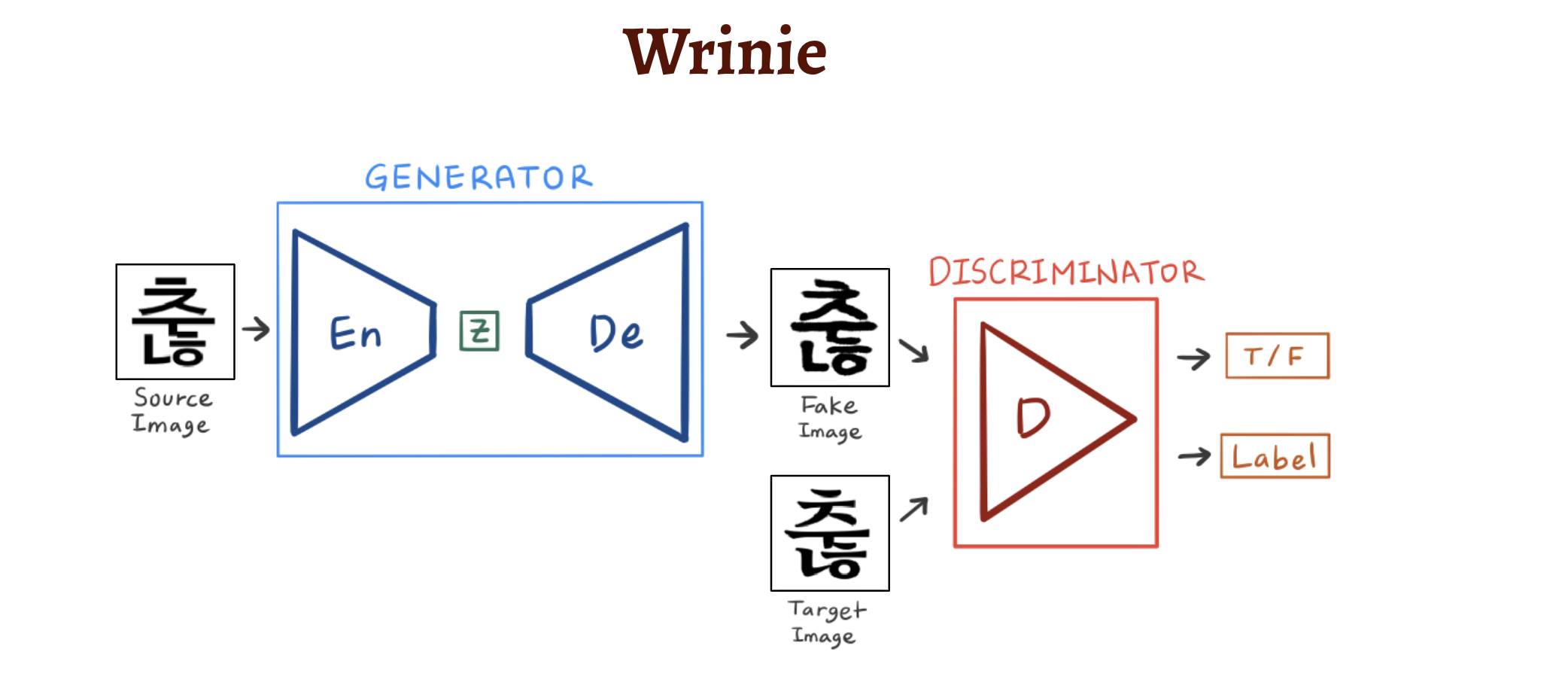
이렇게 Generator 부분은 이미지를 낮은 차원의 벡터로 Mapping 시키는 Encoder와 다시 이미지로 복원하는 Decoder, 두 가지로 구성됩니다.
Decoder 구조만 있는 Original GAN 과는 Generator 의 구조가 사뭇 다르죠!Wrinie의 Generator의 구조와 기능에 대해 조금 더 자세히 살펴보겠습니다.
앞서 언급했듯 Wrinie의 Generator 부분에서는 고딕체를 새로운 글씨체로 바꾸는, 일명 "스타일 변환 (Style Transfer)" 이 이루어져야 합니다. 이를 위해서는 모델에게 변환하기를 원하는 폰트의 카테고리에 대해 입력해 줄 필요가 있습니다.
이 "폰트 카테고리"는Category Vector, 또는Style Vector라는 이름으로 벡터 형태로 모델에 입력될텐데, 다음 그림과 같이 Encoder 를 거쳐 이미지가 낮은 차원에 매핑된 z벡터에 붙여서 입력합니다.즉, 다음 그림과 같이 Encoder로 이미지 특징 추출이 끝난 후 Decoder 에 들어가기 전, z벡터와 함께 Decoder 에 입력됩니다.
따라서 어떤Style Vector를 입력해주느냐에 따라, 내가 원하는 폰트로 변환을 할 수 있게 됩니다.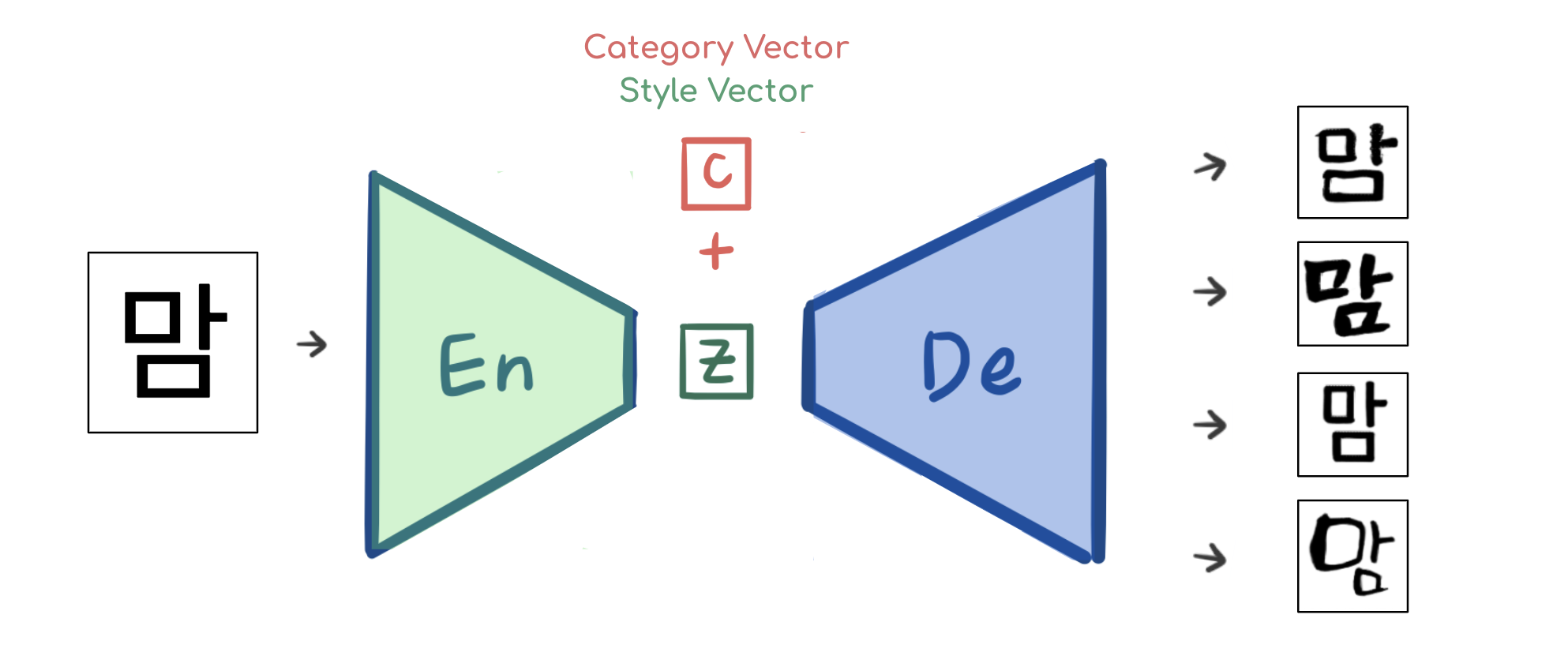
여기서 Style Vector를 Encoder 의 특징 추출이 끝난 후 입력하는 것은 다음과 같은 의미를 가집니다:
- Encoder는 폰트와 관계없이 고딕체 글자를 글자 종류에 따라서만 특징을 효과적으로 추출하는 데에만 집중합니다. 예를 들어, '맘'이라는 글자를 입력받으면 폰트를 고려할 필요 없이
'왼쪽 위에는 ㅁ이 있고, 오른쪽 위에는 ㅏ가, 그리고 밑에는 ㅁ이 있다'는 특징만을 잘 추출할 수 있도록 글자 특징 추출기로써의 역할에 충실하도록 학습합니다. - 반면, Decoder는 Encoder가 잘 추출한 z벡터와 함께 style vector를 입력받으면 글자를 각 style에 따라 복원하도록 학습됩니다.
즉, 이렇게 Encoder 와 Decoder 의 역할을 분명히 구분함으로써 각자는 자기가 맡은 일을 더 잘 할 수 있게 하는 효과를 가지게 됩니다.
마지막으로 Generator의 구조를 3D 형태로 한 번 확인해보시죠!
Encoder와Decoder, 그리고Style Vector까지 모두 확인하면 다음과 같습니다.
여기서 마지막으로 확인할 수 있는 구조는 Encoder에서 단계적으로 축소되어가는 벡터들을 모두 Decoder에 단계적으로 입력하는, [UNet] 구조입니다.
UNet 구조를 개념적으로 이해하자면, 이미지를 복원해야하는 Decoder에게 Encoder에서 추출되는 정보를 추가로 입력해줌으로써 약간의 도움을 주는 것으로 생각할 수 있습니다. 실제로 UNet이 처음 발표된 이후 뛰어난 성능을 인정받았고, 이후 GAN 구조에서도 많이 사용되었습니다.여기까지 고딕체의 이미지를 입력 받으면 어떤 구조를 거쳐 스타일 변환을 하는지, 모델의 구조에 대해 모두 살펴보았습니다.
다음으로는 이러한 모델을 효과적으로 학습시키기 위한 여러가지 손실함수에 대해 알아보도록 하죠!3. Losses, 여러가지 손실함수
GAN 은 학습시키기가 까다롭다고 유명한 모델입니다. ( Why it is so hard to train GAN? )
Generator와 Discriminator가 서로 겨루며 학습한다는 아이디어는 매우 좋아보이지만, 실제로는 그 과정에서 여러 애로사항들이 있습니다.
예를 들어, Discriminator가 똑똑해지는 속도는 매우 빠르지만, Generator가 똑똑해지는 데에는 오랜 시간이 걸리기 때문에 학습 속도면에서 차이가 있습니다. (위조지폐를 검출해내는 것이 빠를지, 걸리지 않을 위조지폐를 밑바닥부터 만드는 것이 빠를지 생각해보면 간단하죠!)
또한, Generator는 Discriminator를 속이는 것만이 목표이기 때문에 다양한 이미지들을 만들기보다는, 안 걸리는 하나의 이미지만을 잘 만드는 쪽으로 학습이 될 수도 있습니다. 이 또한 생각해보면 꽤나 논리적입니다. Generator 입장에서는 어렵게 다양한 이미지들을 만들면서 Discriminator를 속이려고 노력할 필요 없이, 운 좋게 Discriminator가 속아넘어가는 이미지 하나를 잘 만들었다면 그 이미지만 쭉 대량 생산하겠다는 거죠! 이를
Mode Collapse문제라고 하는데, 자세한 내용을 알고 싶다면 [초짜 대학원생의 입장에서 이해하는 Unrolled Generative Adversarial Networks (1)]의 글을 추천드립니다.이렇듯 여러가지의 불안정성 문제로, GAN을 잘 수렴시키기 위해서는 잘 설계된 손실함수가 필요합니다.
Wrinie를 학습시키는 데에는 다양한 손실함수가 사용되었는데, Generator 에 대한 손실함수와 Discriminator 에 대한 손실함수를 구분해서 확인해 보겠습니다.
(손실함수의 설계는 zi2zi 프로젝트의 도움을 받았습니다.)■ Loss of Discriminator
Discriminator의 loss는 간단합니다. 이미지를 입력받으면 진짜 이미지인지, 가짜 이미지인지 판단하는 동시에, 이미지의 폰트 카테고리까지 예측할 것입니다.
이에 따른 Loss는 다음과 같습니다.1) Binary Loss
입력받은 이미지에 대해 Generator가 생성한 가짜 이미지인지, 진짜 이미지인지 구분하는 Loss입니다. 따라서 True / False의 예측 정도를 0~1 사이의 값으로 출력하고, 그 값을 정답(True: 1, False: 0)과 비교합니다.
loss는 두 개의 카테고리(True/False)를 예측하는 이진분류기에 많이 쓰이는 BCE (Binary Cross Entropy) 로 계산합니다.2) Category Loss
입력받은 글자의 폰트 카테고리를 예측하는 loss입니다. 예를 들어, 입력받은 이미지가 1번 폰트인지, 2번인지 또는 10번인지 Multi-class category를 예측해서, 각 폰트 카테고리에 대한 예측값을 역시 0~1 사이의 확률값으로 출력합니다. 이는 Generator가 제대로 된 폰트 스타일을 생성할 수 있도록 도움을 줍니다.
loss는 역시 위와 같은 Cross Entropy로 계산합니다.■ Loss of Generator
Generator는 진짜같아 보이는 이미지를 생성하도록 하는 방향으로 학습합니다. 이를 위한 loss는 다음과 같습니다.
1) L1 Loss

Generator의 가장 기본 목표를 위한 loss 입니다.
Generator가 이미지를 생성하면, 생성된 이미지 (Fake Image)를 타겟으로 하는 진짜 이미지 (Target Image) 와 비교해서 loss를 계산합니다.loss 는 두 이미지를 pixel by pixel 로 비교하는 MAE (Mean Absolute Error) 로 계산됩니다. MAE loss가 크면 두 이미지가 많이 다르다는 의미이므로, Generator는 두 이미지가 비슷해지도록 생성하는 방향으로 학습됩니다.
2) Constant Loss

DTN Network 논문에서 처음 소개된 Constant Loss 는,
생성된 이미지 (Fake Image) 와 고딕체의 원래 이미지 (Source Image) 를 각각 Encoder에 통과시킨 후 만들어지는 z벡터간의 loss입니다.
Encoder는 이미지의 특징을 추출하므로, Fake Image는 Source Image와 비슷한 위치에 매핑되어야 원래 글자의 형태를 잃어버리지 않을 것입니다. 따라서 Constant loss는 두 z벡터가 비슷하게 유지되도록 제어하는 역할을 합니다.
zi2zi 프로젝트의 원작자는 이 Loss를 사용함으로써 수렴 속도가 현저하게 빨라졌다고 설명하였습니다.3) Category Loss
Generator 또한 Discrinimator에 생성한 이미지를 입력해 출력되는 폰트의 카테고리에 대한 점수로 피드백을 받습니다.
Generator는 1번 폰트의 글자라고 생성했는데, Discriminator가 10번 폰트의 글자라고 판별하면 잘 만들지 못한거겠죠?? 이렇게 Generator는 Discriminator가 올바른 폰트 카테고리로 분류할 수 있을만큼 폰트의 특징이 잘 반영된 글자를 만들 수 있도록 학습됩니다.
여기까지 모델이 잘 학습되기 위한 Loss들에 대해서까지 모두 알아보았습니다!
아주 긴 여정이었네요.. 여기까지 Wrinie 프로젝트의 큰 그림 모델의 구조, 그리고 손실함수 등 이론적인 내용들을 담아보았습니다.
이 이후로는 본격적으로 프로젝트의 생생한 진짜 진행 과정을 살펴봐야겠죠! 데이터 전처리부터, 모델을 학습시키는 Hyper Parameter들까지 세부적인 내용들은 다음편인 ☞ 내 손글씨를 따라쓰는 인공지능 요정, Wrinie (2) ☜ 에서 확인하실 수 있습니다.
실험적인 내용들 또한 아주 흥미로울 예정이니 얼른 가보도록 합시다!! ٩(๑˃̶͈̀ ᗨ ˂̶͈́)۶
Acknowledges
- zi2zi: Master Chinese Calligraphy with Conditional Adversarial Networks by kaonashi-tyc
- zi2zi: GitHub Repository by kaonashi-tyc
- AC-GAN
- DTN Network
- pix2pix-tensorflow by yenchenlin
- Domain Transfer Network by yunjey
- ac-gan by buriburisuri
- dc-gan by carpedm20
- origianl pix2pix torch code by phillipi
'Side Projects > 내 손글씨를 따라쓰는 인공지능' 카테고리의 다른 글
내 손글씨를 따라쓰는 인공지능 요정, Wrinie (2) - 실습 (12) 2019.08.16 댓글
- Discriminator는 이미지를 입력받으면 진짜인지 가짜인지에 대한 예측을 0~1 사이의 값으로 확률값을 출력합니다. 출력된 확률값으로 정답