-
내 손글씨를 따라쓰는 인공지능 요정, Wrinie (2) - 실습Side Projects/내 손글씨를 따라쓰는 인공지능 2019. 8. 16. 22:29
#GAN#UNet#Generative Model#CNN#Deep Learning#딥러닝#딥러닝 프로젝트#생성모델#인공지능
본 글은 개인 프로젝트로 진행된 프로젝트에 대한 소개글입니다.
내 손글씨를 따라쓰는 인공지능 요정, Wrinie (1) - 이론 에서는 프로젝트의 큰 그림과 이론적인 내용을,
내 손글씨를 따라쓰는 인공지능 요정, Wrinie (2) - 실습 에서는 프로젝트의 실제 진행 과정에 대한 내용을 담았습니다.
관련 코드는 ↓ 이 곳 ↓ 에서 확인하실 수 있습니다.jeina7/Handwriting_styler
My Handwriting Styler | 내 손글씨를 따라하는 인공지능. Contribute to jeina7/Handwriting_styler development by creating an account on GitHub.
github.com
이 프로젝트는 중국어 글자를 이용해 진행된 zi2zi 프로젝트의 많은 도움을 받았습니다.
모델의 구조, 손실함수 설계 등의 이론적인 부분에서 zi2zi의 내용을 일부 차용하였습니다.
내 손글씨를 기계에게 학습시켜보자!
앞서 말했듯이, 한글은 '모아쓰기' (초성, 중성, 종성을 모아서 한 글자를 만드는 것) 라는 특성으로 인해 단 24개의 자모음 기호만으로도 총 11,172자의 글자를 만들 수 있을만큼 복잡한 언어입니다. 이에 대해 이전 글에서 내 손글씨를 기계에게 학습시키면 어떨까? 라는 아이디어를 제시하며, 많은 시간과 비용이 들어가는 폰트 작업에 생성모델이라는 딥러닝 기술을 접목하는 Wrinie 프로젝트를 소개하였습니다.
다시 한 번 간략하게 확인하자면, Wrinie 프로젝트의 가장 궁극적인 목적은 다음 그림과 같습니다.

디자이너가 직접 많은 시간과 노력을 들여 11,172자의 글자를 모두 작업하는 대신, 약 200자 정도만 사람이 직접 써서 모델에 입력하면 모델이 글씨체의 특징을 스스로 학습해 나머지 11,172자의 글자 전부를 생성하도록 만드는 것입니다.
사람마다 글씨체의 고유한 특징이 있고, 모델이 그 특징을 잡아내어 다른 글씨도 비슷한 글씨체 스타일로 따라쓸 수 있다는 가설 정도라면,
아주 불가능한 일은 아닐 것 같지 않나요? 🤓
그래서 이를 실현시키기 위한 프로젝트의 큰 그림, 모델의 구조, 그리고 모델을 학습시킬 손실함수 등에 대해 이전 글에서 알아보았죠!
그렇다면 이제 더 꾸물대지 않고 바로 프로젝트를 실제로 구현한 내용에 대해 알아보러 가보도록 하겠습니다.
데이터셋은 어떻게 만들었는지, 그리고 Pre-Training 과 Transfer Learning 은 어떻게 진행되었는지, 또한 그 안에 진행한 실험은 무엇이 있는지! 생생한 기록들을 함께 확인하러 이번에도 집중해서 출발해보겠습니다! ᕦ(ò_óˇ)ᕤ
# Contents
1. 내 손글씨를 따라쓰는 인공지능 요정, Wrinie (1) - 이론
1) 프로젝트의 큰 그림
2) 모델의 구조
3) Losses, 여러가지 손실함수2. 내 손글씨를 따라쓰는 인공지능 요정, Wrinie (2) - 실습
4) 데이터셋
5) Pre-Train: 사전학습모델 만들기
6) Interpolation
7) Transfer Learning: 손글씨 학습하기
4. 데이터셋
프로젝트에 대한 이론적인 내용들은 모두 알아보았고.. 이제 Wrinie를 본격적으로 학습시켜 봐야겠죠.
그렇다면 학습에 필요한 데이터셋은 무엇일까요?
모델의 목표를 다시 상기해봅시다.
다음과 같이 고딕체 글자 (Source Image) 를 입력받으면, 모델 내에서 Style Transfer를 수행한 후 글씨체가 입혀진 글자 (Target Image) 를 출력해야 했죠.

따라서, 모델의 기본적인 구조는 다음처럼 Generator와 Discriminator가 합쳐진 GAN 구조였고, 구체적으로 Generator는 입력받은 고딕체 글자를 Latent Space에 Mapping 시켰다가, 다시 이미지로 복원하도록 Encoder와 Decoder로 이루어진 UNet 구조였습니다. 기억나시죠?! 😆
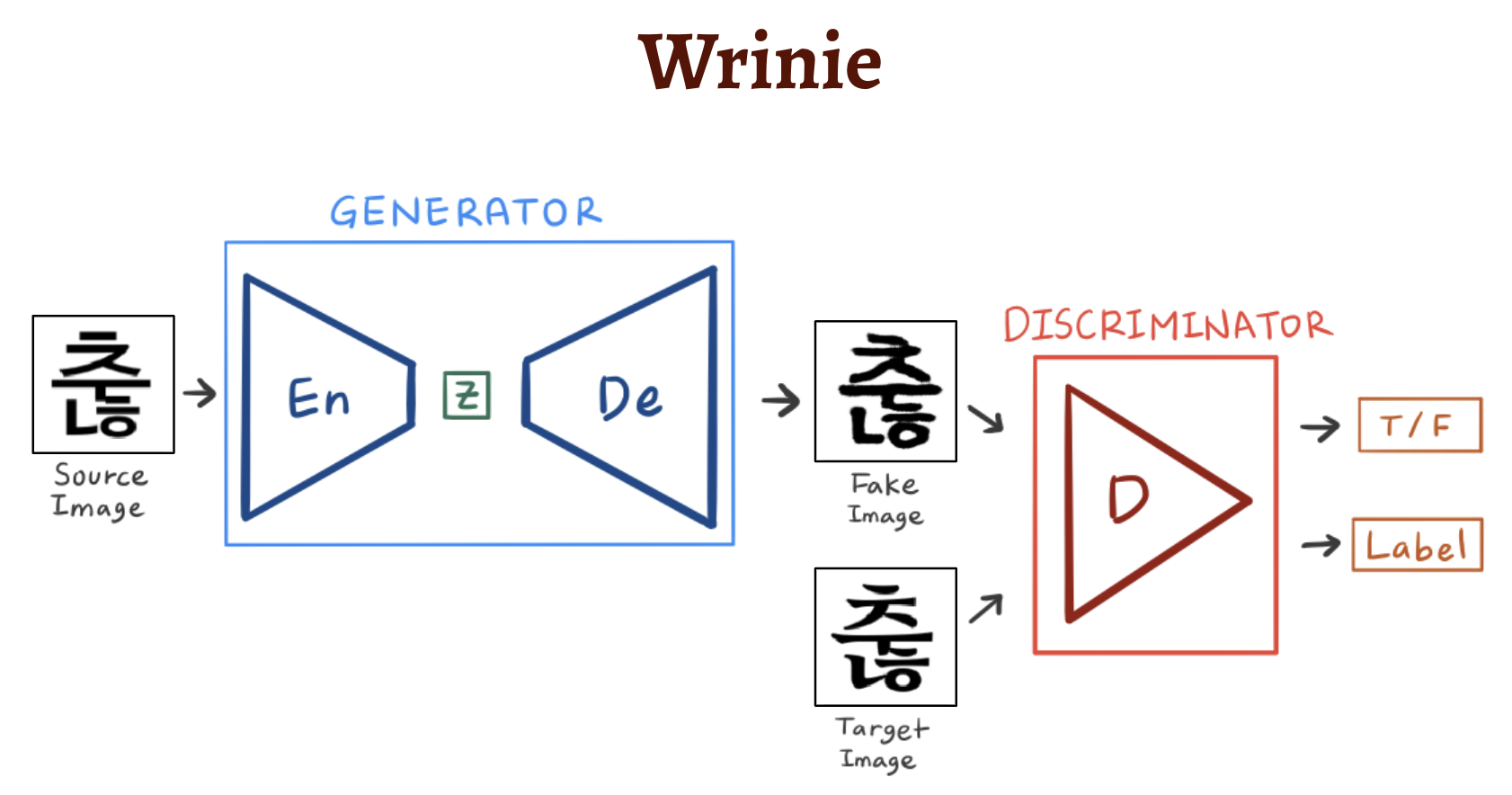
그렇기에! 여기에서 모델에게 필요한 데이터셋은 두 가지입니다. 바로,
1) 입력받을 Source Image인 고딕체 이미지와,
2) 모델이 만들어 낸 Fake Image와 비교하며 잘 만들었는지 아닌지 평가 기준이 될 Label 역할을 하는 Target Image인 여러 폰트의 글자 이미지,
이렇게 둘이 쌍을 이루는 데이터셋이 필요한 것이죠.
따라서 다음과 같이 각 글자에 대해
고딕체 글자와스타일 글자의 쌍으로 이미지를 저장할 것입니다.이렇게 해두면 필요 시 둘을 분리해 쌍으로 바로 사용할 수 있으니 유용하겠죠! (관련 코드: get_data/font2img.py)

Wrinie의 학습에는 (128 x 128) 의 글자 이미지를 사용하므로, 위와 같이 사전에 만들어놓는 데이터셋은 (128 x 256) 의 이미지입니다.
이러한 데이터셋을 총 25가지의 폰트로, 폰트마다 약 3,000자 씩 랜덤으로 선정하여 총 약 75,000장의 이미지를 모델 훈련에 사용할 것입니다.
이 때, 데이터셋을 생성하는 데에는 한 가지 애로사항이 있습니다.
바로 데이터셋의 균질성인데요, 생성된 결과물을 확인해본 결과 python의 PIL 패키지를 이용해 생성한 이미지들은 어쩐지 다음과 같이 (128 x 128) 의 흰 캔버스의 중앙에 잘 그려지지 않는 경우가 있었습니다.

딥러닝의 모델을 학습시키는 데에는 데이터의 품질이 굉장히 중요합니다.
Garbage in, garbage out.이라는 말이 있을만큼, 데이터의 품질은 모델의 학습 효과를 올리고 학습 시간을 단축시킬 Key가 될 수 있습니다. 따라서 데이터의 종류에 상관없이 균일한 데이터, 노이즈가 없는 데이터인지 확인하고, 아니라면 데이터를 적절히 cleansing 해주는 작업은 꼭 필요하다고 할 수 있겠죠!따라서 더 좋은 품질의 데이터셋을 만들기 위해 모든 결과물에 대해 다음과 같이
crop→resize→padding의 과정을 거쳤습니다.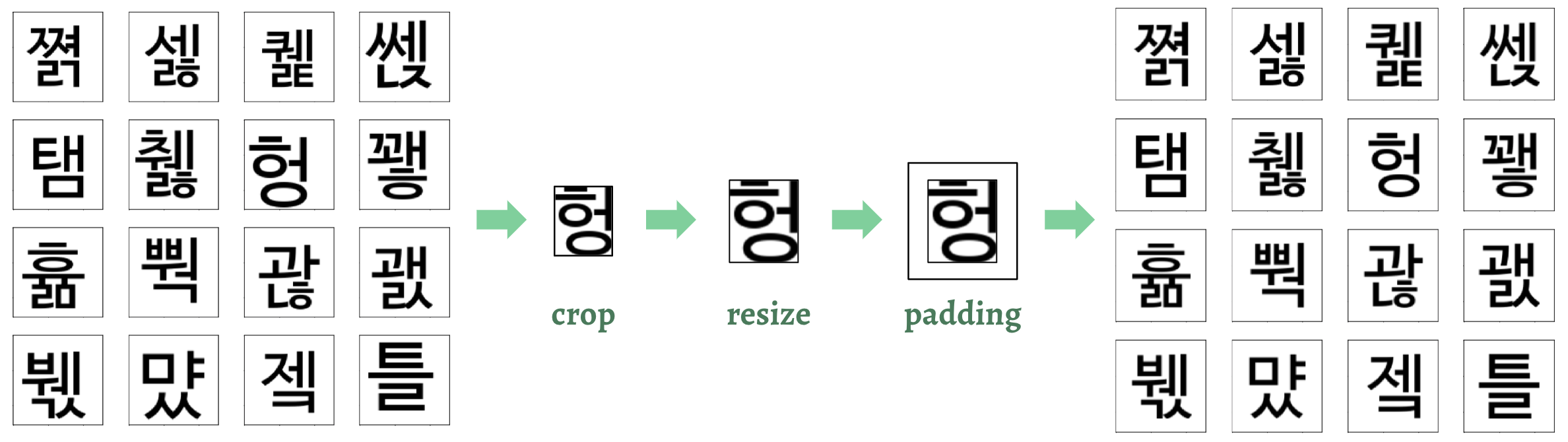
직접 글자를 꽉 채우는 박스에 해당하는 열과 행을 찾아내 slicing하는 방식으로 image crop을 진행한 후, 비율을 유지하며 일정한 크기로 resize하고, 마지막에 상하좌우에 일정한 두께의 padding을 추가하는 것으로 간단히 데이터를 균질하게 만들어냈습니다. (관련 코드: common/utils.py)
여기까지 학습에 필요한 모든 데이터를 생성하고 정제하는 과정까지 거쳤으니, 이제 학습에 바로 쓸 수 있도록 데이터를
.png형식 대신 python에서 파일을 편하게 다룰 수 있는 형식인 pickle 파일,.pkl형식으로 저장할 것입니다.이는 용량이 큰 이미지 파일 대신 byte 형태로 파일을 저장해서 파일을 더 빠르고 가볍게 활용하기 위함입니다! (관련 코드: get_data/package.py)
그럼 이제 드디어 데이터가 모두 준비되었으니 모델을 학습시키러 가보겠습니다! 🤟🏼
5. Pre-Train: 사전학습모델 만들기
모델 학습의 첫 번째 단계, Pre-Train 단계입니다.
이 단계는 무엇보다 대용량의 데이터로 모델이 다양한 폰트를 생성할 수 있도록 학습시키는 것이 주 목표이기 때문에, 데이터 생성이 어려운 사람의 손글씨 대신 컴퓨터 폰트로 학습을 진행합니다. 바로 위에서 생성한 데이터셋을 사용하는 거죠!
약 75,000장의 데이터셋으로 총 150epoch 정도 진행될 Pre-Train 과정은 다시 다음과 같은 두 단계로 세분화됩니다
[1단계] Training from Scratch: 밑바닥부터 학습하는 단계 (30epoch)
[2단계] Further Training for Sharp Image: 보다 뚜렷한 이미지로 개선하는 단계 (120epoch)
위 두 단계는 모두 같은 75,000자의 데이터셋으로 학습하지만, 차이점은 Loss에 있습니다.
앞서 알아본 3. Losses, 여러가지 손실함수 의 내용에서, Generator의 loss 중
L1 loss와Constant Loss, 두 가지를 기억하시나요?이 두 가지 Loss는 모두 Generator의 손실함수로써, 생성된 Fake Image를 평가해서 각 손실함수의 평가 결과값에 따라 Generator가 올바른 방향으로 학습이 될 수 있도록 한다는 공통점이 있었습니다. 하지만 Fake Image를 평가하는 방식에 있어서는 다소 차이가 있었죠.
두 Loss를 간단한 그림으로 표현하면 다음과 같습니다.

둘은 어떤 차이가 있을까요?
먼저,
L1 Loss는 Generator가 생성한 Fake Image를 정답에 해당하는 Target Image와 직접 비교합니다.반면,
Constant Loss는 Target이 아닌 고딕체의 Source Image와 비교하는데, 이 때 글자 이미지를 직접 비교하는 대신 각각의 이미지를 Encoder를 통과시켜 생성되는 z 벡터끼리 비교합니다. 앞서 설명했듯, Generated 된 Fake Image의 글자 형상이 원래 글자인 고딕체의 글자 형상에서 크게 벗어나지 않도록 제어하기 위함이죠.이렇게 비교 대상에서 차이가 나는 L1 Loss와 Constant Loss는 그 효과 또한 다소 다릅니다.
L1 Loss는 생성한 이미지를 정답 이미지와
pixel by pixel방식으로 비교하므로, Generator는 L1 Loss를 줄이기 위해서 디테일에 집중하는 대신 전체적인 형상을 뭉뚱그려 그리게 되는 경향을 가지게 됩니다. 즉, L1 Loss는 빠르게 수렴하면서 전체적인 형상을 잡을 수 있도록 하는 효과가 있으므로 밑바닥부터 학습해야 하는 [1단계] Training from Scratch 에서 L1 Loss를 중심으로 학습합니다.하지만 이 단계가 너무 길어지면 세부적인 형태는 잡지 못한 채로 흐릿한 글자를 생성하게 되기 때문에, 적절한 시기에 이 단계를 끝내는 것 또한 중요합니다.
특히, 아래 글자와 같이 필기체 형태의 복잡한 글자같은 경우에는 L1 Loss만으로는 절대 아무리 학습을 지속해도 제대로 된 결과물을 만들어낼 수 없습니다.
L1 Loss의 한계점이죠..!

필기체의 "푈"과 같은 복잡한 글자는 [1단계] 에서 잘 학습하지 못함 그래도 이렇게 특별히 어려워하는 글자를 제외한다면 L1 Loss만으로도 30epoch 정도 학습시켰을 때 다음과 같이 전체적으로 어느정도 글자의 형태를 알아볼 수 있는 결과물을 생성할 수 있습니다.

[1단계] Training from Scratch (30epoch) 학습 결과 하지만 자세히 보면 글자의 마무리 부분이 깔끔하지 않고, 각 글씨체의 특징이 완벽하게 구분되지는 않는 것 같습니다. 그렇다면 이제 디테일에 신경을 써봐야겠죠!
그래서 다음 단계인 [2단계] Further Training for Sharp Image 에서는 Constant Loss를 중심으로 학습합니다.
Constant Loss는 보다 세부적인 부분을 뚜렷하게 만드는 데에 유리하므로, L1 Loss로는 잡아낼 수 없는 디테일들을 살릴 수 있습니다!
하지만 이 단계의 치명적인 단점은.. 초기의 30epoch보다 학습이 훨씬 느리고, 효과도 더디게 나타나기 때문에 많은 인내심이 필요하다는 것입니다. 🙀
(이 부분이 GAN 학습 악명의 진가를 느낄 수 있는 부분인데, 혹자는 그저 Loss가 오르락내리락 하는 것을 보며 해가 뜨고 지는 것을 기다렸다고 했더랬죠.. 😂)
그렇게 오랜 시간을 견뎌낸 후 만들어진 결과물은!
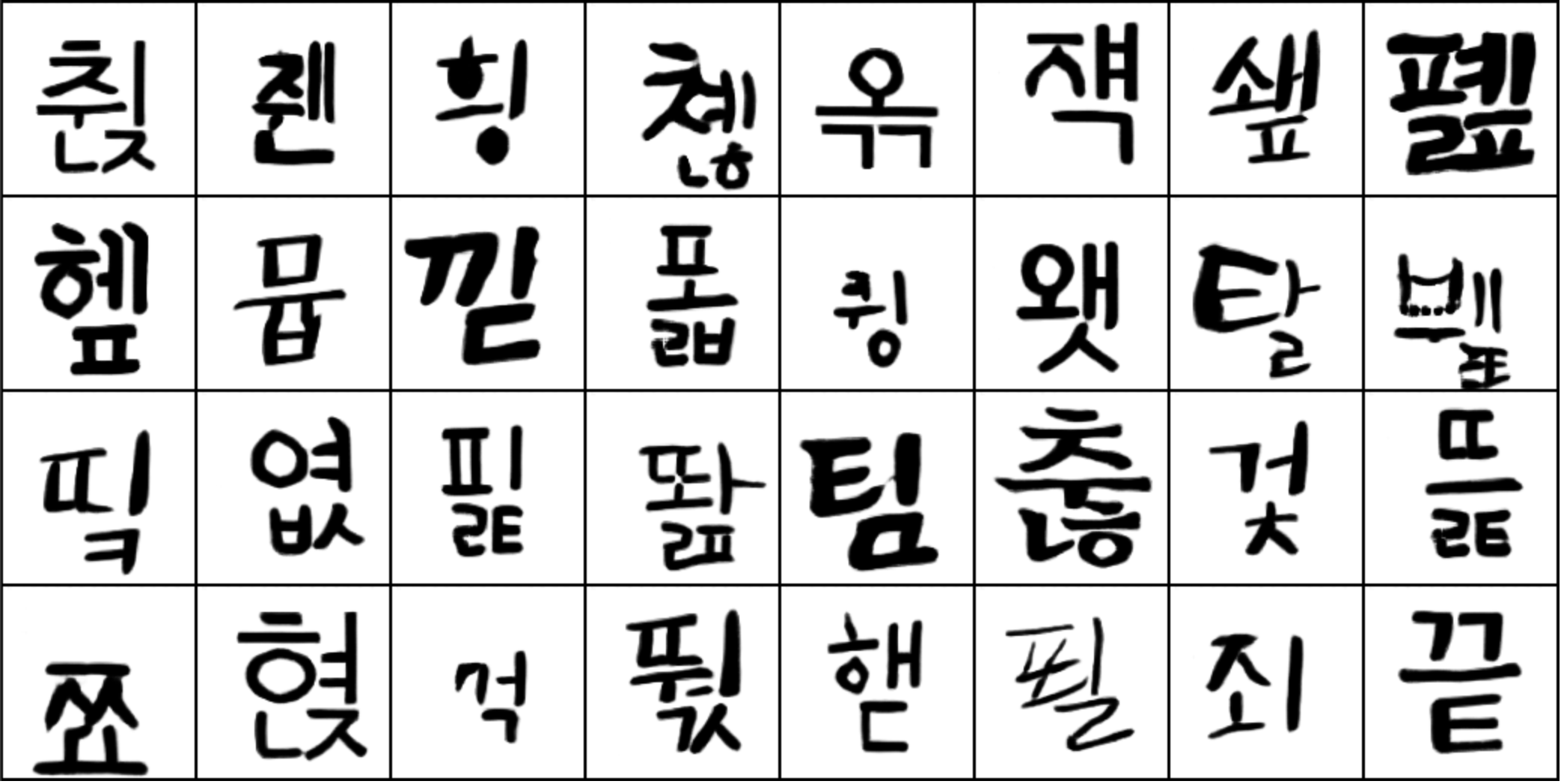
[2단계] Further Training for Sharp Image (120epoch) 학습 결과 어때요? 언뜻 보면.. 사실 아주 큰 차이는 없는 것 같은가요 😅
하지만, 디테일은 생명인걸요! 글자들을 조금 더 자세히 뜯어보면, 훨씬 더 정교하고 각 글씨체의 특징이 드러나는 형상으로 개선된 것을 확인할 수 있습니다.
특히, 아까는 못 잡았던
푈글씨가 완벽한 형상으로 그려진 것은 꽤나 인상깊은 발전이지 않나요?이렇게 두 단계로 이루어진 Pre-Train 전체 과정을 전체적으로 살펴보면 다음과 같습니다.

Pre-Train 전체 과정 (150epoch) 처음에는 바둑판모양처럼 아무 의미 없는 이미지에서 시작해서, 학습이 진행됨에 따라 점점 글자의 형상을 갖춰나가는 것을 볼 수 있죠!
150epoch에 거의 다다를 즈음에는 특히 글자가 깔끔해지는 것도 볼 수 있습니다! :)
- 150epoch의 총 학습시간은 NVIDIA의 P100 GPU를 사용했을 때 약 50시간 소요됩니다.
- 모델 구조 관련 코드 : common/models.py
- 학습 관련 코드 : common/train.py
사전학습모델이 이렇게 완성되었습니다! 👏🏼👏🏼👏🏼
고딕체의 글자를 입력받았을 때 Encoder가 효과적으로 글자의 특징을 추출하고, Decoder는 입력받은 폰트 카테고리 정보에 따라 폰트 스타일이 반영된 글자를 생성할 수 있는 모델이 준비된 것입니다.
그렇다면 이 사전학습모델로는 어떤 흥미로운 것들을 할 수 있을까요?! 바로 확인하러 가보시죠. 🤓
6. Interpolation
프로젝트의 최종 단계인 사람의 손글씨를 학습하기 전에, Interpolation 이라는 아주 흥미로운 실험을 하나 해보겠습니다!
이번에도 결과를 먼저 확인해보죠.
다음 그림이 바로 폰트와 폰트 간의 Interpolation이 이루어진 모습입니다. 마치 글자가 살아 숨쉬는 것 같지 않나요?

Interpolation은 GAN의 개념이 Ian Goodfelllow를 통해 2014년 처음 세상에 나온 후 (Goodfellow et al. 2014), 딥러닝을 접목시킨 DCGAN 논문에서 처음으로 진행되었던 실험입니다 (Radford et al. 2015).
이 논문에서는 이 실험에 대해
Walking in the latent space.즉잠재공간을 걷다.라고 표현했습니다.이게 무슨 말이냐 하면.. 모델이 학습한 잠재 공간은 매우 높은 차원이기 때문에 사람은 그 영역을 직관적으로 이해할 수 없습니다. (Wrinie의 경우 z 벡터의 벡터공간은 512차원입니다!) 하지만 이 실험, Interpolation을 통해서 우리는 간접적으로나마 유의미한 잠재공간이 존재한다는 것을 확인할 수 있고, 나아가 그곳을 탐색한다는 의미로써 "잠재공간을 걷다." 라는 은유적인 표현을 쓴 것이죠.
그렇다면, 도대체 Interpolation 의 엄밀한 개념은 무엇일까요?
사전에서 단어의 뜻을 찾아보면 '보간법'이라고 나오고, 이를 위키백과에서는 "수치해석학의 수학분야의 용어로써, 알려진 데이터 지점의 고립점 내에서 새로운 데이터 지점을 구성하는 방식" 이라고 정의합니다. 흠.. 🤔
어려운 말로 고민하기보다, Wrinie에서 이루어진 Interpolation 실험을 바로 확인하면서 저 말의 의미를 이해해보도록 하겠습니다.
모델에게 폰트의 종류를 입력해주기 위해서, Encoder를 거쳐서 특징이 추출된 z 벡터에 카테고리 벡터인 c 벡터를 붙여 Decoder에 입력한 것을 기억하시나요?
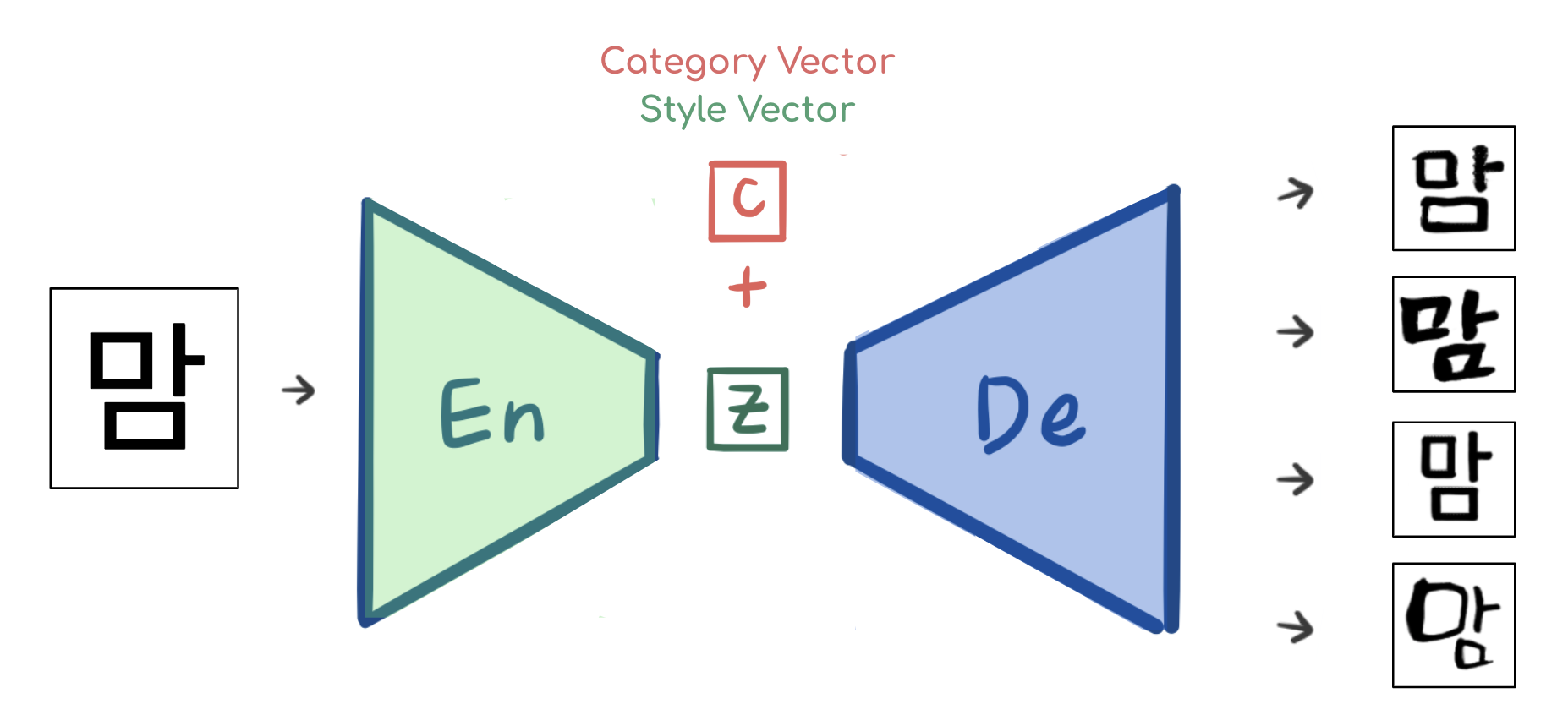
바로 이 그림이었죠!
여기에서, 분홍색으로 표시된 c 벡터, 즉
Category Vector또는Style Vector로 불리는 녀석이 바로 폰트를 결정짓는 카테고리 벡터였습니다.보통 데이터 사이언스 분야에서 카테고리를 구분할 때에는
Label Encoding,One-Hot Encoding의 두 가지 방식이 많이 사용됩니다.예를 들어,
[사과, 오렌지, 수박, 포도]의 카테고리가 있는 경우, 위의 두 가지 방법은 각각 다음과 같은 표현방식으로 카테고리를 나타냅니다.Label Encoding:사과=1,오렌지=2,수박=3,포도=4One-Hot Encoding:사과=[1, 0, 0, 0],오렌지=[0, 1, 0, 0],수박=[0, 0, 1, 0],포도=[0, 0, 0, 1]
즉,
Label Encoding은 카테고리마다 각각 다른 숫자를 부여해 Label(숫자)로써 각 카테고리를 구분하는 반면,One-Hot Encoding은 카테고리 개수만큼의 길이를 가지는 벡터를 이용해 표현합니다. 이때 각 벡터에는 단 하나의1이 있고 나머지는 모두0으로 채워지는데, 1의 위치를 모두 다르게 함으로써 모든 카테고리를 구분할 수 있습니다.하지만, Wrinie는 위의 잘 알려진 두 가지 방법이 아닌 새로운 방법을 사용합니다.
구글이 2017년 발표한 신경망을 이용한 기계번역에 관한 논문 (Melvin et al. 2017) 에서 쓰인 방식으로, Gaussian Normal Random Vector를 이용합니다. 즉, 가우시안 분포에서 랜덤으로 추출한 벡터를 이용해 카테고리를 구분하는 것입니다.
이렇게 했을 때의 이점은 무엇일까요? 다음의 그림들을 함께 보며 이해해보죠!
실제로 Wrinie에서는 랜덤 벡터를 128차원의 벡터로 사용했는데, 128차원은 우리가 표현할 수도, 상상할 수도 없으므로 설명을 위해서 2차원 벡터라고 가정하고 간단히 시각화 해보겠습니다.
랜덤 벡터를 모두 좌표상에 표시해 본다면, 모든 벡터는 다음과 같이 벡터 공간에 점으로 표현할 수 있을 것입니다.
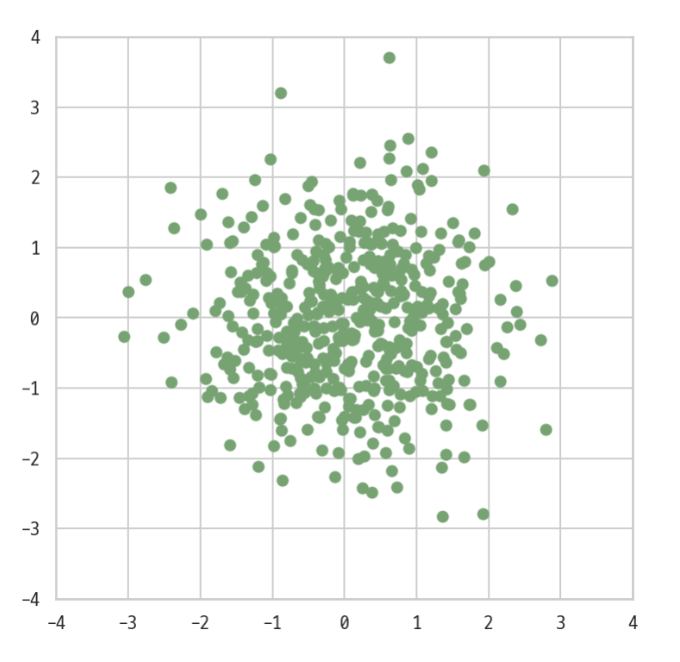
이렇게 여러 벡터가 흩뿌려진 좌표 공간에서 다음과 같이 서로 다른 두 가지의 폰트 카테고리가 좌표상에 ★로 표시된 점 두 곳에 위치한다고 가정해보겠습니다.

이런 경우, 우리는 이런 상상을 해볼 수 있습니다.
왼쪽 폰트가 ★에 위치하고, 오른쪽 폰트가 ★에 위치할 때, 모델이 효과적으로 벡터공간을 학습했다면 두 점 사이에 위치한 점들 또한 유의미하지 않을까?
즉, 다음 그림과 같이 ★과 ★사이에 있는 점들을 카테고리 벡터로 모델에 입력해준다면, 왼쪽 폰트와 오른쪽 폰트가 적당히 섞인 중간 폰트의 글자를 눈으로 확인할 수 있지 않을까? 라는 물음을 던져볼 수 있는거죠.
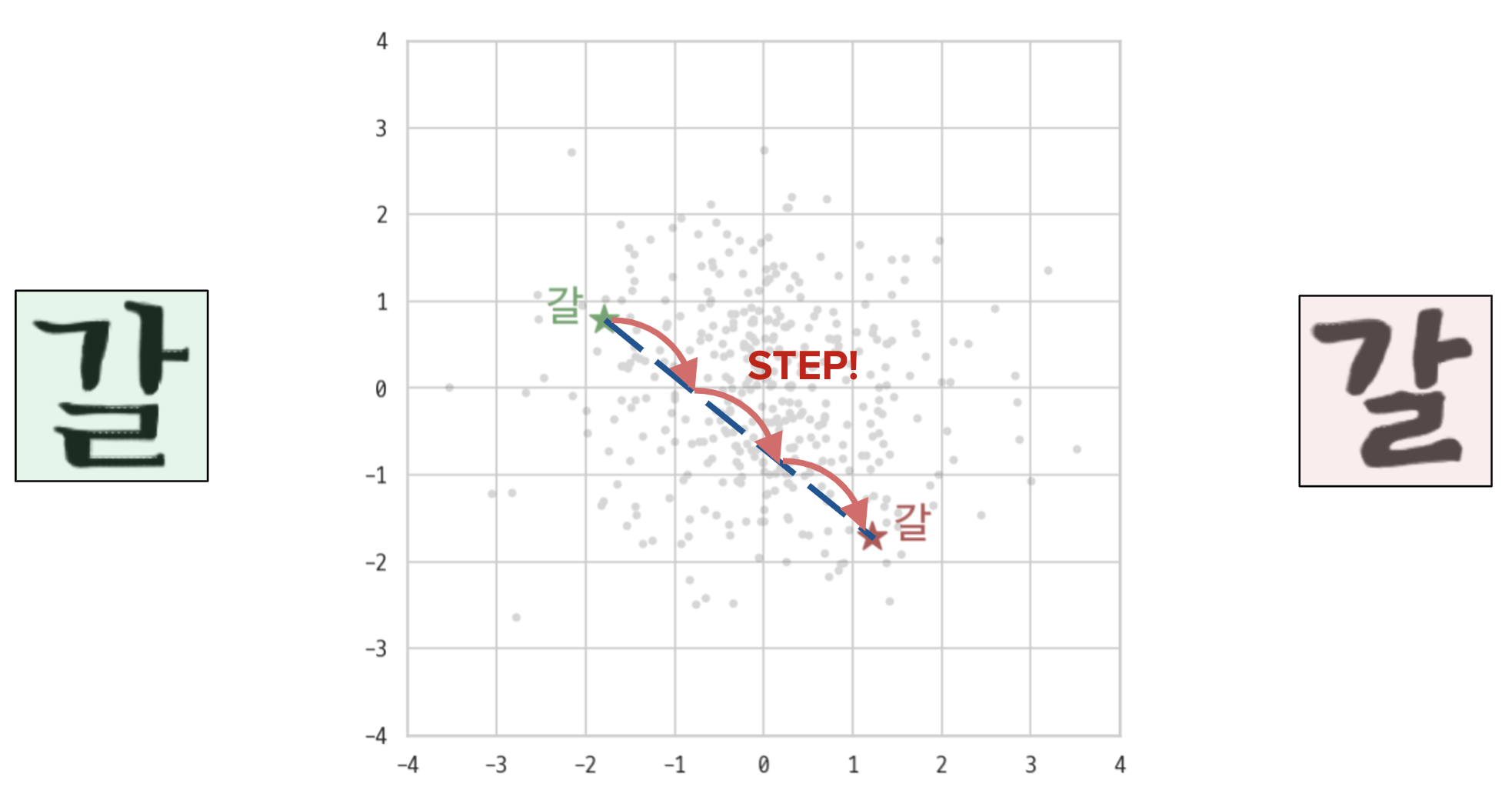
이게 된다면 꽤나 흥미로울 것 같은데, 실제로도 유효한 가설일까요?
잘 학습된 Pre-Trained 모델을 이용해서 실험을 진행한 결과, 다음과 같이 흥미로운 결과가 나타났습니다.
위에서 본 두 가지 폰트를 양 끝 점으로 잡고, 왼쪽 폰트에서 출발해서 오른쪽 폰트로까지 일정한 간격을 주어 점을 이동하며 모델에게 입력하면 다음과 같은 결과를 확인할 수 있습니다.

어떤가요?
왼쪽에서 오른쪽으로 갈 수록, 확실히
ㅏ모양은 끝의 꺾임이 점점 없어지면서 두꺼워지고,ㄹ또한 얇은 정자체에서 두꺼운 흘림체로 변해가는 것을 확인할 수 있습니다.이를 여러가지 글자, 여러가지 폰트에 대해 구현해본 결과는 다음과 같습니다!

각 글자를 자세하게 가만히 보고 있으면 각 모음, 자음이 형태를 부드럽게 바뀌어가는 것을 확인할 수 있습니다.
정말 흥미로운 결과가 아닐 수 없죠!
이 실험 결과는 모델이 카테고리 벡터 공간을 효과적으로 학습했다는 것을 반증할 뿐만 아니라, 학습 데이터로 주어진 폰트 외에도 훨씬 많은 결과물을 생성할 수 있다는 증거가 되기도 합니다. 모델의 활용 가능성이 훨씬 높아짐을 의미하는 것이죠!
예를 들어, 같은 폰트이지만 얇은 글자와 두꺼운 글자, 두 가지를 모두 모델이 학습했다면 모델은 두 가지 두께 사이의 모든 두께의 글자를 생성해낼 수 있을 것입니다. 단지 카테고리 벡터를 두 폰트 사이의 벡터로 입력하는 것만으로요!
이쯤에서 다시 Interpolation의 정의를 읽어보면, "알려진 데이터 지점의 고립점 내에서 새로운 데이터 지점을 구성하는 방식" 이라고 합니다. 이제는 이 뜻이 명확히 이해가 되는 것 같지 않나요? (۶•̀ᴗ•́)۶
여기까지 모델의 학습이 제대로 이루어졌다는 확인과 더 넓은 활용 가능성을 보여준 Interpolation 에 대한 소개해 보았습니다.
이제 드디어! 프로젝트의 마지막 단계인, 사람의 손글씨 학습 단계로 달려가보시죠!!
7. Transfer Learning: 손글씨 학습하기
Wrinie의 손글씨 학습은 바로 제 손글씨를 이용해서 시도해보았습니다.
손글씨를 학습시키기 위해서는 먼저 데이터가 필요하겠죠!
Wrinie에게 입력해줄 데이터 생성을 위해, 210자의 글자 템플릿을 만들고 그 위에 직접 글자를 쓰는 방식으로 데이터를 생성하였습니다.
210자는 모델이 학습하기 어려운 복잡한 글자와 많이 사용되는 비교적 쉬운 글자에 대해 균형잡힌 학습을 할 수 있도록, 11,172자의 모든 음절에서 실제로 많이 쓰이는 2,350자 중 절반 정도를, 그리고 많이 쓰이지 않는 나머지 글자에서 절반 정도를 랜덤으로 추출해 선정하였습니다.

210자 템플릿 위에 글씨를 직접 써넣은 모습 이렇게 글자를 모두 쓴 후, 손글씨 데이터 또한 이전에 생성한 데이터처럼 고딕체와 쌍을 이룬 데이터로 생성하고, 균질한 데이터가 되도록
crop→resize→padding의 데이터 클렌징 작업을 진행하였습니다.이제 데이터가 준비되었으니 모델을 학습시킬 차례인데, 이번의 학습은 210자라는 아주 적은 양의 데이터만으로 학습을 해야하기 때문에 이전에 약 75,000자의 방대한 데이터로 미리 학습을 시켜놓은 사전학습 모델을 사용할 것입니다.
즉, 이전 글에서 언급한 Transfer Learning을 하는 것이죠!
다시,
Transfer Learning이란 이미 학습이 되어있는 모델을 다른 데이터셋이나 다른 목적의 프로젝트에 입맛에 맞게 적용시켜 사용하는 것이었죠!이 때 사전학습 모델을 어떻게 사용할 지는 자유롭습니다. 모델 전체를 학습된 상태 그대로 쓸 수도, 또는 일부분만 그대로 쓰고 나머지는 새로 학습을 시킬 수도 있죠. (여기서 일부분이란 모델의 일부 계층, 즉 Layer를 의미합니다.)
이는 새로 학습할 데이터의 양과 사전에 학습한 데이터와 새로 학습할 데이터 사이의 연관성에 따라 달라질 수 있습니다.
두 데이터 간의 연관성이 크면 사전에 학습된 많은 부분을 십분 활용할 수 있겠지만, 연관성이 적다면 많은 부분을 새로 학습시켜야 할 수 있습니다.
또한, 새로 학습할 데이터의 양이 아주 많다면 모델이 그 데이터에 대해 새롭게 잘 학습될 여지가 크므로 많은 부분을 새로 학습시켜도 되지만, 양이 적다면 모델을 제대로 학습시키기 어렵기 때문에 적은 부분만 새로 학습시켜야 할 수 있습니다.
이런 Transfer Learning의 전략에 대한 더 많은 디테일은 [Transfer Learning | 학습된 모델을 새로운 프로젝트에 적용하기] 에서 확인하실 수 있습니다.
그렇다면 Wrinie의 상황은 어떤가요?
새로 학습할 데이터(사람의 손글씨)는 이전에 학습한 데이터(컴퓨터 글씨)와 유사한 데이터라고 볼 수 있지만, 데이터의 양이 현저히 작기 때문에 모델을 아주 많이 새로 학습시킬 수는 없을 것 같습니다. 즉, 이전에 학습된 파라미터를 많이 재활용 해야할 것 같다는 생각이 듭니다.
다만, 모델의 Encoder는 고딕체의 이미지를 입력받아 글자의 특징을 추출하는 역할을 하는 부분이었기 때문에 이전 상황과 달라질 게 없으므로 새로 학습시킬 필요가 전혀 없습니다! Encoder는 잘 학습된 글자 특징 추출기 (Feature Extractor) 로써 사용하면 될 것 같습니다.
따라서 다음과 같이 세 가지 정도 단계로 실험을 진행해볼 수 있을 것 같네요!
1. Encoder를 모두 얼리고(freeze), Decoder 또한 상당부분(7 layer 중 5 layer)를 얼리는 것
2. Encoder를 모두 얼리고, Decoder를 조금만(7 layer 중 2 layer) 얼리는 것
3. Encoder를 모두 얼리고, Decoder를 모두 새로 학습시키는 것

이 세 가지 실험을 모두 진행해본 결과를 확인해보죠.
1번 실험의 결과, Decoder에게 너무 적은 자유도를 주어서인지 학습이 제대로 이루어지지 않았습니다. 조금 더 자유도를 주어야 할 것 같네요.

1. Encoder를 모두 얼리고, Decoder는 7 layer 중 5 layer를 얼린 결과 2번 실험의 결과는 다음과 같습니다.

2. Encoder를 모두 얼리고, Decoder는 7 layer 중 2 layer를 얼린 결과 글씨가 어느정도 보이는 것 같아요! 하지만 아주 잘 학습되었다고는 할 수 없을 것 같습니다.. 마구 깨진 글씨들이 많이 보이는군요.
결과적으로는 Encoder만 그대로 사용하고, Decoder는 통째로 새로 학습시킨 3번 실험이 가장 좋은 결과를 보여줬습니다.
데이터의 양이 적어서 Decoder를 새로 학습시키기보다 많은 부분을 그대로 사용해야 될 것이라고 생각했는데, 보여지는 결과는 그렇지 않았습니다.
아마 제 주관적인 생각으로는, Encoder가 잘 학습되어있고 Decoder가 복원하는 과정에서 또한 Encoder의 도움을 받기 때문에 (UNet 구조) Decoder는 데이터가 적은 것이 크게 문제되지 않고 전체를 새로 학습시켜도 잘 학습이 되는 것 아닐까 합니다!
좋은 결과를 보여준 3번 실험의 결과물과 제가 직접 쓴 진짜 글씨를 함께 확인해보겠습니다.

왼쪽: 모델이 생성한 글씨 / 오른쪽: 내가 진짜 쓴 글씨 앞에서 봤던 결과물보다는 확실히 깔끔한 결과를 확인할 수 있습니다. 특히
ㅁ을 보면 밑부분에 흘림을 주는 특징도 잘 잡아낸 것을 볼 수 있죠!그렇다면, 마지막으로! 제가 템플릿에 써서 모델에게 보여준 210자 외의 나머지 글자들에 대한 결과도 확인해보죠!
모델은 210자 외의 다른 글자들은 제가 어떤 스타일로 쓰는지 한 번도 본 적이 없지만, 제 글씨체의 특징을 제대로 학습했다면 나머지 글씨도 비슷한 스타일로 잘 써낼 수 있어야 할테니까요..!
[내 손글씨를 따라쓰는 인공지능]의 13자는 전부 템플릿의 210자에 포함되지 않은 글자입니다.이 글자들을 제가 직접 한 번 써 보고, 모델이 생성한 글씨와 비교해본 결과를 확인해보면..!

위: 내가 직접 쓴 글씨 / 아래: 모델이 생성한 글씨 흠.. 어떤가요? 결과물이 사실 아주 깔끔하지는 않아보입니다.
더 깔끔한 결과물을 낼 수 있도록 일련의 필터링 또는 클렌징같은 개선작업을 추가하면 좋을 것 같습니다.
하지만, 스타일에 대해 확인해보면 한 번도 안 본 글씨 치고는 제 스타일을 꽤나 반영해준 것 같지 않나요? 😆
여기까지, [내 손글씨를 따라쓰는 인공지능 요정, Wrinie] 프로젝트의 전체 과정에 대한 소개를 마칩니다.
결과물이 바로 활용을 해도 될만큼 아주 완벽하지는 않지만, GAN을 응용한 모델이 제대로 학습되었다는 점, 그리고 그 이론과 실습에 대해 깊숙이 알아보았다는 점에서 큰 의의가 있는 것 같아요 😊
여기까지 긴 시간동안 함께 달려와주시고 부족한 글을 모두 읽어주셔서 감사드립니다! 저에게도 참 긴 여정이었네요..
혹 내용이 너무 많아 지루하지 않았을까 하는 걱정이 되기는 하지만, 누군가에게라도 흥미있게 읽히면 좋겠다는 큰 바람을 가져봅니다 (੭•̀ᴗ•̀)੭
혹시 잘 안읽힌 부분이 있거나, 궁금한 점이 있다면 언제든 질문 주시면 더 좋은 글이 되는데에 큰 도움이 될 것 같습니다! 감사합니다 :)
Acknowledges
'Side Projects > 내 손글씨를 따라쓰는 인공지능' 카테고리의 다른 글
내 손글씨를 따라쓰는 인공지능 요정, Wrinie (1) - 이론 (1) 2019.07.20 댓글