강화학습 개념부터 Deep Q Networks까지, 10분만에 훑어보기
#강화학습 #Transfer Learning #DQN #DeepQNetworks #딥러닝 #MDP #MarkovDecisionProcesses
이 글은 원작자의 허락 하에 번역한 글입니다!
중간 중간 자연스러운 흐름을 위해 의역한 부분들이 있습니다.
원 의미를 왜곡시키지 않도록 노력하였지만, 부족한 부분이 분명 있을거라고 생각합니다.
어떤 지적이나 조언이든 해주신다면 감사히 받고 더 나은 글을 쓰기 위해 노력하겠습니다.
원문은 ↓ 이곳 ↓ 에서 보실 수 있습니다.
Qrash Course: Reinforcement Learning 101 & Deep Q Networks in 10 Minutes
Learn the basics of Reinforcement Learning and Deep Q Networks from scratch — exercise included!
towardsdatascience.com
이 글은 신경망에 대한 기초 이해는 있지만, 강화학습에 대한 사전 지식은 없다는 가정 하에 작성되었습니다.
많고 다양한 머신러닝 분야들 중에서, 저를 가장 매료시켰던 것 중 하나는 바로 강화학습입니다. 이 분야와 아직 많이 친하지 않은 사람들을 위해 잠깐 짚고 넘어가자면 — 지도학습(Supervised Learning)은 정답이 주어진 데이터로 학습해서 새로운 데이터에 대한 값이나 카테고리를 예측하고, 비지도학습(Unsupervised Learning)은 정답이 없는 데이터를 적절히 그룹화하거나 각 데이터 간의 관계를 찾아냅니다.
반면, 강화학습(Reinforcement Learning)은 어떤 임의의 존재 (Agent) 가 주어진 환경 내에서 어떻게 행동해야 하는지에 대해 학습하는 것을 다룹니다. 이러한 학습 과정은 다양한 상황에서 Agent가 한 행동에 대해, 양 또는 음의 보상으로 피드백을 받음으로써 진행됩니다.
제가 강화학습을 배우면서 실용적으로 많이 쓰인 것 중 하나는 Deep Q Networks인데, 강화학습을 처음 접하면서 함께 공부하면 좋을 것 같아 함께 다루어볼 예정입니다. 이해하기 쉬운 가장 간단한 예제부터 함께 시작해보도록 하겠습니다. 가보시죠! ٩(◕ᗜ◕)و
강화학습의 세상 — 환경, 상태, 행동, 그리고 보상
강화학습의 최종 목표는 환경(Environment)과 상호작용을 하는 임의의 Agent를 학습시키는 것입니다. Agent는 상태(State)라고 부르는 다양한 상황 안에서 행동(Action)을 취하며 조금씩 학습해 나갑니다. Agent가 취한 행동은 그에 대한 응답으로 양(+)이나 음(-), 또는 0의 보상(Reward)을 돌려받습니다.
여기에서 Agent의 목표는 처음 시작하는 시점부터 종료시점까지 일어나는 모든 에피소드에서 받을 보상값을 최대로 끌어올리는 것입니다. 이를 위해 음(-)값의 보상을 받는 행동은 최대한 피하도록 하고, 양(+)값의 보상을 받을 수 있는 행동을 강화시킨다는 의미에서 강화학습이라는 이름이 붙게 되었습니다. 이렇게 Agent가 학습을 하는 과정에서 점점 발전하게 될 의사결정 전략을 정책(Policy)라고 합니다.
강화학습의 한 예로 슈퍼 마리오를 들어보겠습니다. 마리오는 그 게임의 세상, 즉 환경(Environment)과 상호작용을 하는 Agent입니다. 상태(State)는 매 순간 스크린에 보여지는 그 이미지이고, 한 에피소드는 게임의 한 판이 시작되는 시점부터 끝나는 시점까지의 내용이라고 할 수 있겠죠. 이 때, 끝나는 시점은 그 판을 클리어하는 순간이 될 수도, 또는 마리오가 죽게되는 순간이 될 수도 있습니다.
Agent가 취할 수 있는 행동(Action)은 '앞으로 이동', '뒤로 이동', '점프' 등이 될 것입니다. 각각의 행동에 따라 보상은 달라질 수 있는데, 예를 들어 마리오가 코인을 먹거나 보너스 아이템을 얻은 경우 양(+)의 보상을 받고, 떨어지거나 적에게 맞아서 죽게 되는 경우 음(-)의 보상을 받도록 설계할 수 있습니다. 마리오가 그냥 아무것도 하지 않고 여기저기 돌아다니기만 한다면 그냥 특별한 것 없이, 보상은 0이 되겠죠.

그러나, 여기에는 한 가지 고려해야 하는 점이 있습니다. 바로 보상을 얻기 위해서는, 어느 정도의 "특별하지 않은", 즉 보상이 0인 행동들이 꼭 필요하다는 것이죠 — 예를 들어 코인을 얻기 위해서는, 코인이 있는 곳으로 걸어가야 합니다. 하지만 그냥 걷는 것에 대해서는 보상이 주어지지 않죠. 이러한 특징 때문에, Agent는 어떤 행동이 실제로 보상을 발생시켰는지에 대한 연결고리를 찾아서 "지연된 보상"을 잘 얻을 수 있도록 학습하는 것이 중요합니다.
개인적으로는, 바로 이 부분이 강화학습의 가장 매력적인 포인트라고 생각합니다.
Markov Decision Processes, 마코프 결정 프로세스
모든 상태(State)는 그 직전의 상태와, 그 상태에서 Agent가 선택한 행동이 만든 직접적인 결과입니다. 직전의 상태는 또한 그 이전의 상태와 그 이전의 상태에 한 행동의 결과이고, ... 이렇게 계속하다보면 처음 시작했던 시점까지 올라갈 수 있겠습니다. 이렇게 연결되어 있는 모든 단계들과 그 순서는 현재 상태를 결정짓는 어떤 정보를 담고 있을 것이고, 그에 따라 지금 순간에 Agent가 어떤 행동을 선택해야 하는지에 대해서도 직접적인 영향을 미칩니다. 즉, 모든 정보들을 다 활용할 수 있다면 Agent가 어떤 선택을 해야하는지 결정하는 데에 큰 도움이 될 것입니다.
하지만 이런 식이라면 한 가지 문제가 발생합니다. 바로 Agent가 한 단계씩 나아갈 때마다, 점점 더 많은 정보들이 저장되어야 하고 그 양은 계속 늘어난다는 점이죠. 이렇게 많은 양의 데이터를 다루면서 연산한다는 것은 쉽지 않은 일입니다.
이 문제를 해결하기 위해서, 우리는 모든 상태가 Markov State에 해당한다고 가정합니다. Markov State란, "모든 상태는 오직 그 직전의 상태와 그 때 한 행동에 대해서만 의존한다"는 가정입니다. 즉, 직전 상태 말고 그보다 더 이전의 상태들에 대해서는 고려하지 않아도 되는 것이죠. 바로 한 가지 간단한 예를 Tic-Tac-Toe 게임으로 살펴보겠습니다.
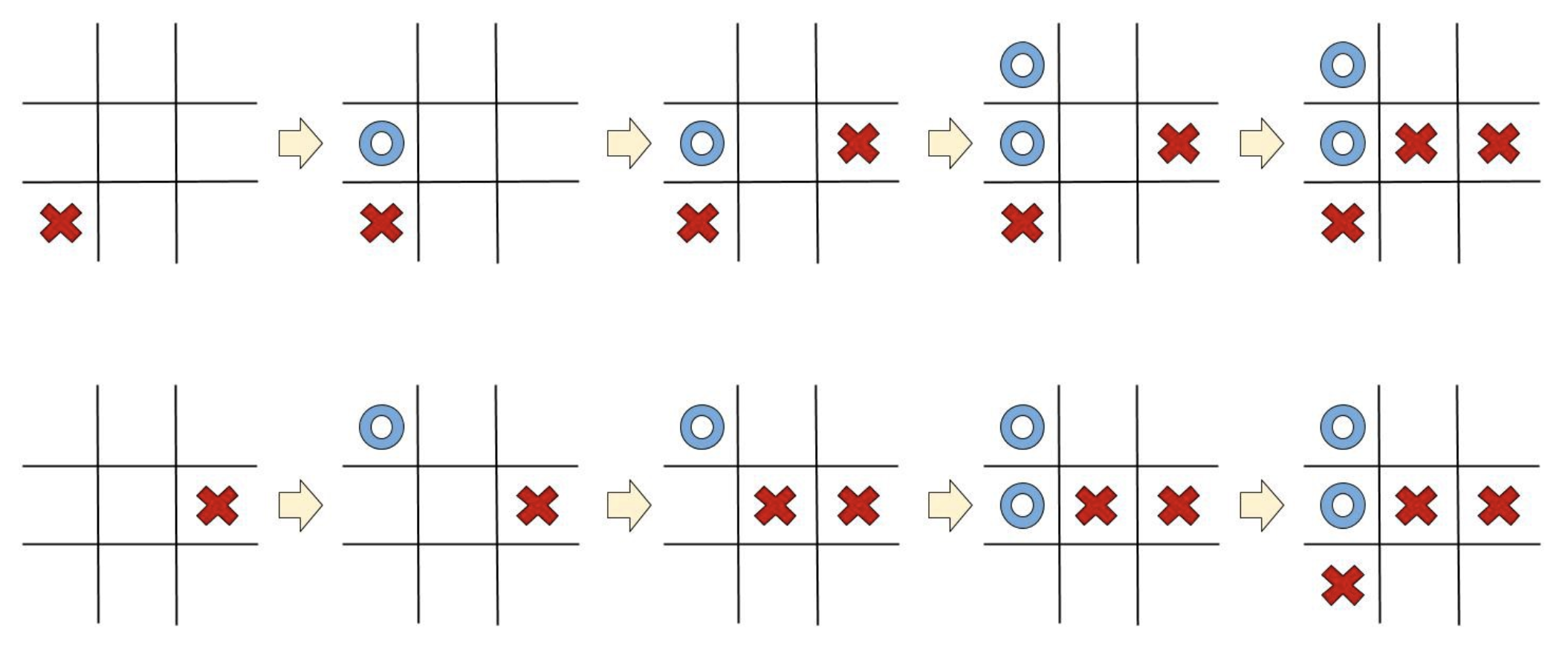
위쪽과 아래쪽, 두 게임 모두 결과적으로 맨 오른쪽을 보면 같은 상태에 도달했지만, 그 과정은 다릅니다. 또한, 두 게임 모두 마지막 상태에서 파란색 플레이어는 맨 오른쪽 위의 칸에 다음 수를 둬서 상대방을 잡지 못하면 지게 됩니다. 이렇게 Tic-Tac-Toe 게임은 우리가 매 순간 행동을 선택하는 데에 있어서 고려해야 하는 것은 오직 직전의 상태일 뿐, 그 이전에 어떤 경로를 통해서 그 상태에 도달했는지는 고려하지 않아도 됩니다.
이러한 가정이 바로 Markov assumption인데, 이 가정을 이용하면서 기억해야 할 점은 상황이 진행됨에 따라 데이터를 잃게 된다는 것입니다. 위와 같이 단순해서 Markov assumption이 정확히 맞아 떨어지는 Tic-Tac-Toe는 문제가 없지만, 더 복잡한 게임인 체스나 바둑같은 게임에서는 게임이 진행되어가는 경로에 상대방의 의도나 전략 등의 정보들이 담겨있을 수 있기 때문입니다. 하지만, 그럼에도 불구하고 Markov assumption은 장기 전략을 짜는데에 가장 기본적인 가정으로 많이 쓰입니다.
The Bellman Equation, 벨만 방정식
그럼 이제 본격적인 내용으로 들어가봅시다. 가장 단순한 경우부터 생각해보죠. 우리는 모든 상태에서 취하는 각각의 행동에 대해 보상을 얼마나 받을지 미리 알고 있다고 가정해보겠습니다. 이 경우 우리는 행동을 어떻게 결정하면 될까요? 간단하게, 최종적으로 가장 높은 보상을 받을 수 있는 행동들을 연속적으로 취하면 될 것입니다. 이렇게 최종적으로 받는 모든 보상의 총합을 Q-value (Quality Value의 약자입니다) 라고 합니다.
$$Q(s, a) = r(s, a) + \gamma \max_a Q(s', a)$$
벨만 방정식
하나하나 살펴보겠습니다. 상태 $s$ 에서 행동 $a$ 를 취할 때 받을 수 있는 모든 보상의 총합 $Q(s, a)$ 는, 현재 행동을 취해서 받을 수 있는 즉각보상과 미래에 받을 미래보상의 최대값의 합으로 계산할 수 있습니다. 우변의 $r(s, a)$ 는 현재 상태 $s$ 에서 행동 $a$ 를 취했을 때 받을 즉각보상값을 나타냅니다. 또한, $s'$ 은 현재 상태 $s$ 에서 행동 $a$ 를 취해 도달하는 바로 다음의 상태로, $\max_a Q(s', a)$ 는 다음 상태 $s'$ 에서 받을 수 있는 보상의 최대값입니다. 이 값을 최대화 할 수 있는 행동을 선택해내는 것이 Agent의 목표입니다.
또한 그 앞에 붙어있는 $\gamma$ 는 할인율이라고 부르는 값으로, 미래가치에 대한 중요도를 조절합니다. $\gamma$ 값이 커질수록 미래에 받을 보상에 더 큰 가치를 두는 것이고, 작아질수록 즉각보상을 더 중요하게 고려하는 것입니다.
이 방정식을 벨만 방정식이라고 합니다. 더 자세한 설명과 수학적 유도 과정은 위키피디아에서 확인할 수 있습니다. 이 우아한 공식은 다음 두 가지 성질때문에 강화학습에서 굉장히 유용합니다.
- Markov States 가정이 유효하다면, 벨만 방정식의 재귀적인 성질은 미래에 받을 수 있는 보상을 멀리 떨어진 과거로까지 전파될 수 있게 한다.
- 벨만 방정식의 재귀적인 성질은 또한, 처음에 실제 $Q$ 값이 얼마인지 알지 못해도 괜찮도록 한다. 즉, 처음에는 추측으로 값을 정하지만, 점점 수렴해서 마지막에는 정답 값에 도달할 것이다.
Q Learning
이제 우리는 "어떤 상태이든, 가장 높은 누적 보상을 얻을 수 있는 행동을 취한다" 라는 기본 전략이 생겼습니다. 이렇게 매 순간 가장 높다고 판단되는 행동을 취한다는 점에서, 알고리즘은 greedy (탐욕적) 이라고 부르기도 합니다.
그렇다면 이런 전략을 현실 문제에는 어떻게 적용시킬 수 있을까요? 한 가지 방법은 모든 가능한 상태-행동 조합을 표로 그리고, 거기에 모든 Q-value를 적어 사용하는 것입니다. 그 후에는 벨만 방정식을 이용해서 표를 점점 업데이트해 나갈 수 있겠죠.
$$Q(s, a) := r(s, a) + \gamma \max_a Q(s', a)$$
여기서 ':=' 라는 표현은 '같다'는 의미보다, '할당된다' 는 뜻을 강조하기 위해 쓰였습니다.
더 얘기할 것 없이, 바로 예를 한번 보시죠!
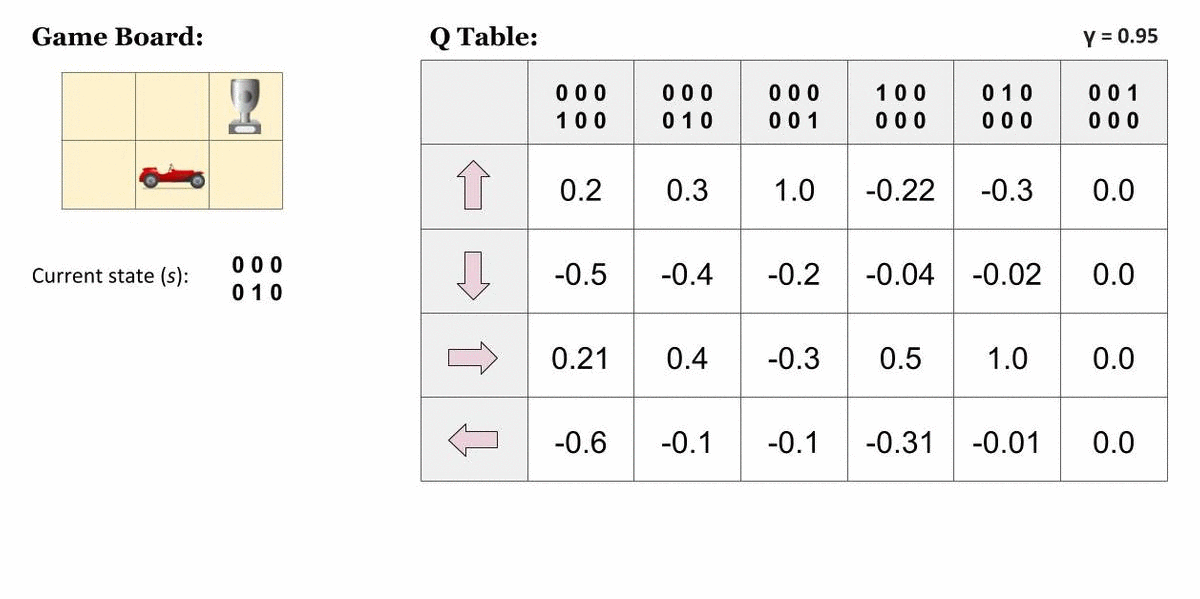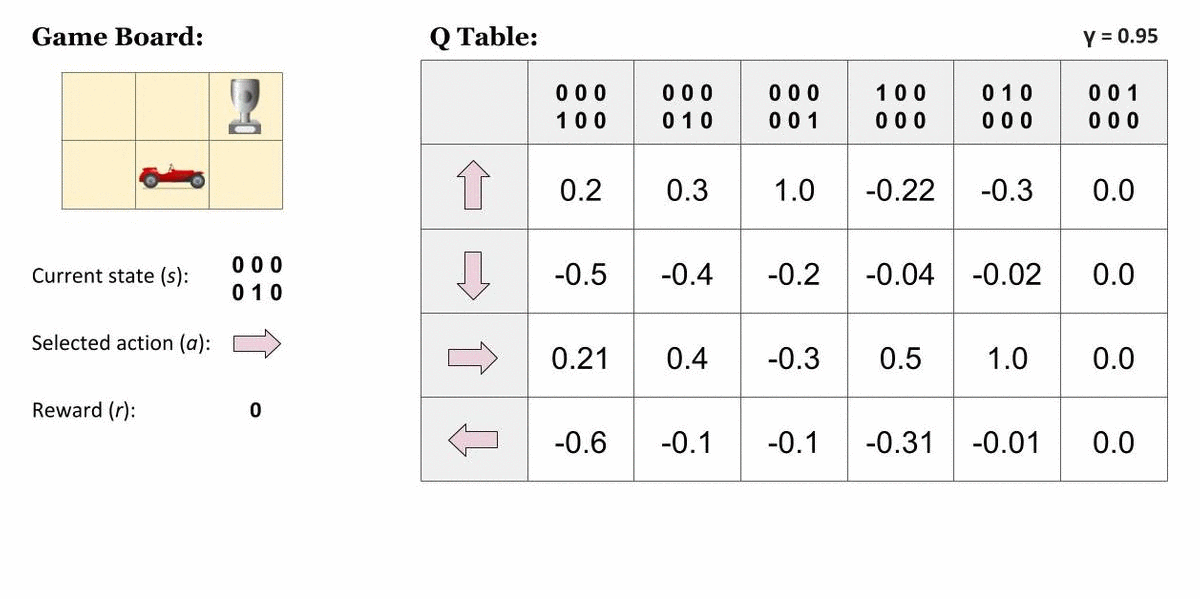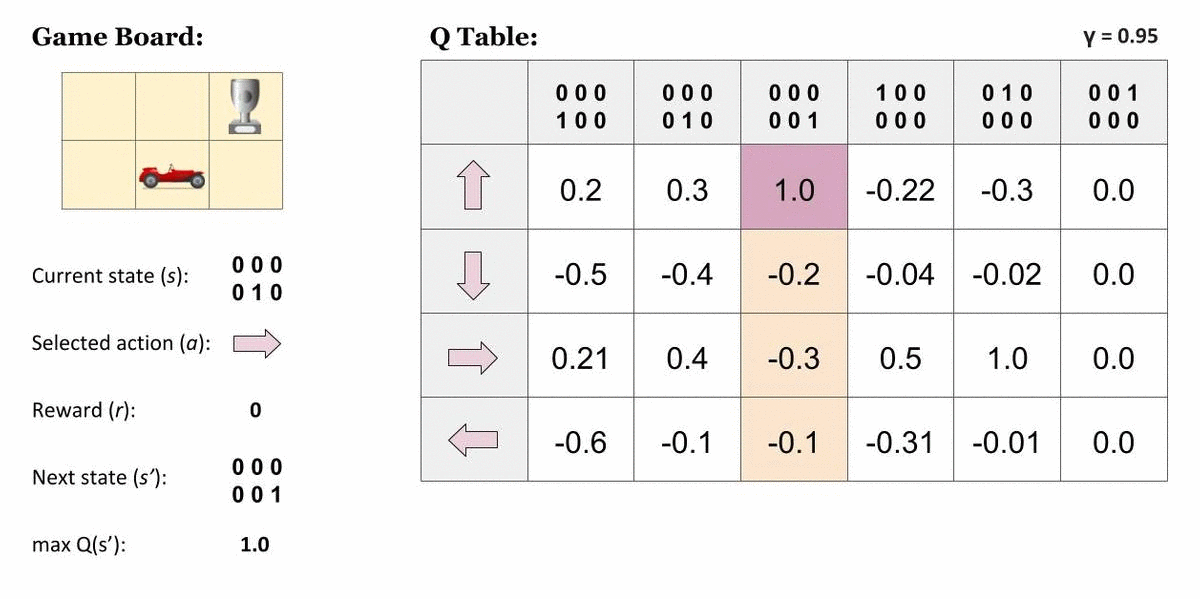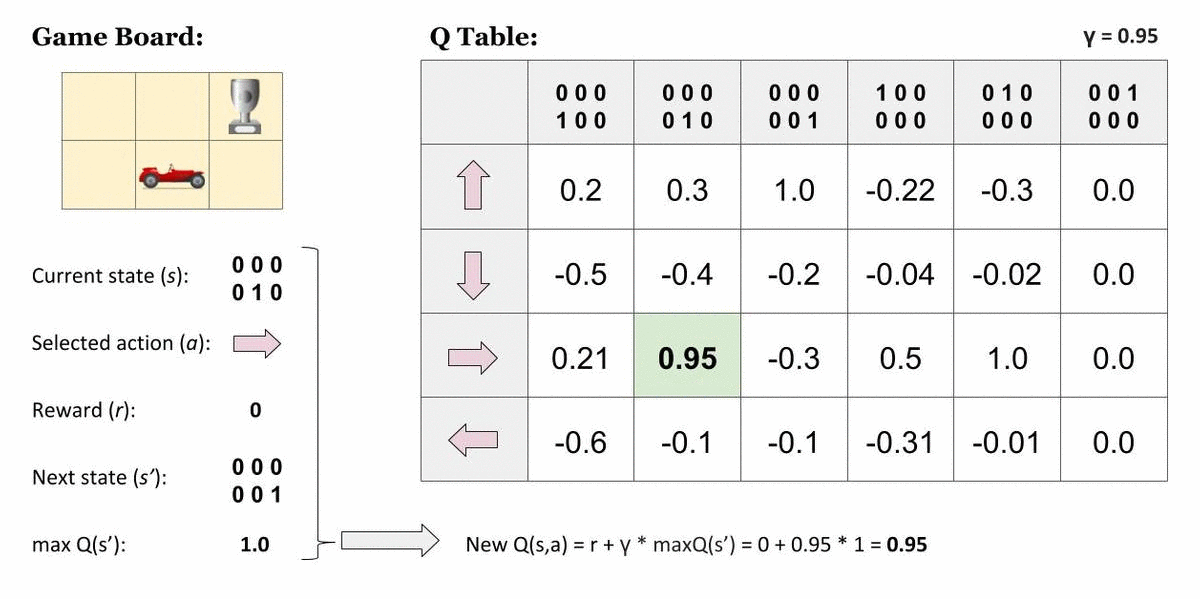
여기서 Agent가 가장 오른쪽 위 칸에 도달하면 게임이 끝납니다. 즉, 표에서 맨 오른쪽 열이 나타내는 상태는 종결상태입니다. 이 상태에서 Agent는 아무런 행동 또는 상태 변화를 할 수 없기 때문에 모든 값은 0입니다. 그렇다면, 종결상태인 $s'$ 에 도달하기 직전의 상태에 대해서는 이렇게 단순히 그 다음 순간 받을 즉각 보상으로만 가치를 산정할 수 있을 것입니다. 다음처럼요!
$$Q(s, a) = r(s, a)$$
여기서, 한 가지 더 문제가 있습니다. 우리의 탐욕적 알고리즘은 심각한 문제가 하나 있죠. 만약 항상 '최선의 선택'만 고집한다면, 새로운 선택은 해보지 않을 것이고, 그렇게 된다면 아직 받아보지 못한 미지의 보상에 대해서는 앞으로도 그 존재를 알 수 없을 것입니다. 그것을 받기 위한 시도를 안 할 테니까요.
이 문제를 해결하기 위해, 우리는 $\epsilon - greedy$ 전략을 추가합니다. 바로 $0<\epsilon<1$ 인 어떤 $\epsilon$ 값을 이용해서, 탐험과 활용을 적절히 번갈아가며 사용하는 것입니다. $p=1-\epsilon$ 의 확률로는 원래 했던 대로 탐욕적으로 행동을 선택하고, 나머지 $p=\epsilon$ 의 확률로는 랜덤으로 행동을 취하는 것입니다. 이렇게 함으로써 Agent는 새로운 공간으로의 탐험을 해보면서 알지 못하는 것들도 놓치지 않고 학습할 수 있는 기회를 가지게 되는 거죠.
이 알고리즘을 바로 Q Learning, 즉 Q-러닝이라고 합니다. (혹은 표를 이용한다는 점을 따서, Q-table이라고도 합니다.)
축하합니다! 이제 강화학습의 첫 번째 알고리즘을 다 배웠습니다! 😆👏🏼👏🏼👏🏼
Deep Q Networks
Q-러닝을 배운 지금, 아마 Q-러닝이 다룰 수 있는 데이터의 스케일에 대해 궁금할 수도 있을 겁니다. 만약 아직 궁금하지 않았더라도, 한 번 생각해봅시다. 만약 존재 가능한 상태와 행동의 가짓수가 아주 방대하다면 어떨까요? 실제로 그런 방대한 문제들은 꽤 흔하기도 하죠.
심지어, 아주 간단한 게임인 Tic-Tac-Toe 게임만 해도 수백 가지가 넘게 가능한 '상태'가 있고, 여기에 각 상태에서 취할 수 있는 '행동'이 최대 9가지까지 가능하다는 점을 생각해보면 아주 방대한 양이 될 것입니다. 간단한 게임에서도 벌써 이 정도라면, 진짜 복잡한 문제들은 어떻겠어요?
그래서 여기서 딥러닝을 떠올려볼 수 있습니다. Q-러닝과 딥러닝을 합친 것을 바로 Deep Q Networks 라고 부릅니다. 아이디어는 심플해요. 위에서 사용했던 Q-table 대신 신경망을 사용해서, 그 신경망 모델이 Q 가치를 근사해낼 수 있도록 학습시키는 거죠. 그래서 이 모델은 주로 approximator (근사기), 또는 approximating function (근사 함수) 라고 부르기도 합니다. 모델에 대한 표현은 $Q(s, a; \theta)$ 라고 하고, 여기서 $\theta$ 는 신경망에서 학습할 가중치를 나타냅니다.
그렇다면 신경망을 학습시키기 위한 목적함수, 또는 비용함수를 설정해야 할텐데, 어떤 값을 최소화하면서 학습해나가면 될까요? 일단 위에서 가치를 산정하는 식이었던 벨만 방정식을 다시 한 번 살펴보겠습니다.
$$Q(s, a) = r(s, a) + \gamma \max_a Q(s', a)$$
학습해나가는 과정에 있어서 "=" 라는 기호는 '할당'이라는 의미를 가집니다. 하지만 좌변과 우변이 실제로 같아지는 순간은 언제일까요? 네, 바로 Q 가치가 수렴해서 참값에 도달했을 때 두 값은 완벽히 같아집니다. 우리가 학습시키고자 하는 최종 목적지도 바로 이것이죠! — 그러므로 우리는 두 값의 차이를 최소화하는 방향으로 모델을 학습해나가면 될 것 같습니다. 그렇다면, 비용함수는 다음과 같은 식으로 간단히 정의되겠죠!
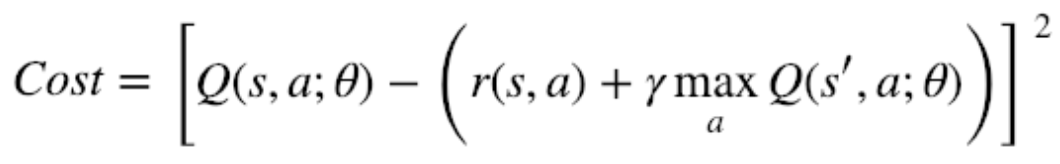
어라, 이 방정식 어디서 많이 본 것 같지 않나요? 네, 맞습니다. 바로 Mean Square Error function, 즉 평균 제곱근 오차 형식과 많이 닮은 것 같아요. 만약 현재 Q-value를 예측값 $y$ 라고 하고, 벨만 방정식의 우변에서 계산된 즉각보상과 미래가치의 합을 $y'$ 라고 한다면, 다음과 같은 식으로도 표현되겠네요.

이런 성질 때문에 $Q(s', a; \theta)$ 는 Q-target 이라고 불리기도 합니다.
이제 학습 과정에 대해 좀 더 살펴봅시다. 강화학습에서는, Training data set이라는 게 처음에는 따로 없습니다. Agent가 행동을 취함에 따라 데이터셋은 점점 쌓여나가는 거죠. Agent는 매 순간 그때까지 학습된 네트워크를 통해 최적이라고 판단된 행동을 취하면서, 에피소드가 끝날 때까지 상태, 행동, 보상, 그리고 다음 상태에 대한 데이터를 쌓아나갑니다.
데이터를 쌓으면서 학습하는 과정은 이렇습니다. 학습에 필요한 batch size를 $b$ 라고 한다면, Agent는 행동을 $b$ 번 취하면서 $b$ 개의 데이터 세트들이 기록합니다. 여기서 주목해야 할 점은, 우리는 저장되어있는 메모리 공간에서 방금 기록된 $b$ 개의 데이터셋으로 학습하는 것이 아니라, 지금까지 쌓인 데이터셋 중 $b$ 개를 랜덤으로 선택해서 신경망을 학습시킨다는 점입니다.
(딥마인드의 David Silver에 따르면, 직전에 쌓인 $b$ 개의 데이터셋을 그대로 사용하면 그 데이터 간에는 상관관계가 너무 크기 때문에 학습이 제대로 이루지지 않아서 랜덤으로 추출한 데이터셋으로 학습을 시킨다고 합니다.)
메모리를 저장하는 저장소의 형태는 몇 가지 종류가 있는데, 그 중 가장 많이 쓰이는 것은 cyclic memory buffer입니다. 이는 Agent가 학습에 관련없는 데이터들보다, 조금 더 의미가 있을 최신의 데이터로부터 학습할 수 있도록 도와줍니다.
점점 구체적인 내용으로 들어가고 있는 것 같군요. 그렇다면 이제 모델의 구조에 대해서 한 번 확인해 보시죠. 단순히 위에서 봤던 Q-table에서 봤던 방식에 따른다면, 신경망은 현재 상태에 대한 정보와 현재 취할 행동, 두 가지를 입력받습니다. 그 후에는 모델 내에서 연산을 거쳐 Q-value를 출력하게 되죠. 다음과 같은 형태가 될 것 같습니다.

하지만, 여기 한 가지 고려해야 할 점이 있습니다. 위의 형태는 틀린 구조는 아니지만, 비효율적인 면이 있죠. 벨만 방정식에서 우리는 가치를 최대화하기 위해 미래에 선택할 수 있는 행동에 따른 가치 중 최대값을 취해야 하는 부분이 있었습니다. $\max_a Q(s', a)$ 부분, 기억하시나요? 그렇다면, 최대값을 찾기 위해서는 모든 행동들을 취해봐야 알 수 있을 것입니다. 신경망 연산을 여러번 돌려야 하는 것이죠. 그렇기 때문에, 우리는 위의 구조 대신 아래의 구조로 조금 변형해서 사용할 것입니다.

모델을 이렇게 수정하면 우리는 모델에 상태만을 입력해줬을 때 각 행동에 대한 모든 Q-value를 한 번에 얻을 수 있습니다. 훨씬 낫군요!
그래서 여기까지, 우리는 거의 다 배웠습니다. 다시 축하합니다! 방금 Deep Q Network를 설계하는 방법을 배운 겁니다!
Bonus — Double Deep Q Learning
마무리 하기 전에, 한 가지만 더 보겠습니다. 조금 전에 Deep Q Network의 비용함수와 Mean Square Error를 비교했던 것, 기억하시나요? MSE는 정답값 $y$ 와 예측값 $y'$ 를 비교했었습니다. 여기서 보통의 기계학습에서 정답값 $y$ 는 학습을 하는 과정 중에 변하지 않는 상수값이죠. 하지만, Deep Q Networks에서는 상황이 다릅니다. $y$ 와 $y'$ 둘 다 신경망이 출력하는 값이기 때문에, 매 학습 단계마다 많이 달라질 수 있습니다. 이로 인한 학습 성능 저하 또한 당연히 발생하겠죠.
그래서 여기서 한 가지 소개되는 것이 — Double Deep Q Network 입니다. semi-constant 인 레이블을 사용하는거죠. 어떻게 하냐구요?
바로, Q Network의 사본을 만들어서, 하나는 계속 업데이트가 되도록 하는 대신, 다른 하나는 그대로 남아있도록 하는 방법을 사용합니다. 그리고 상수로 사용하는 네트워크는 가끔씩만 새로 학습된 네트워크로 업데이트를 해주는 거죠. semi-constant라는 이름은 이러한 이유로 붙게 되었습니다. 그래서 이에 대한 비용함수는 다음과 같아집니다.

여기서, $\vartheta$ 는 semi-constant 파라미터이고, $Q(s', a; \vartheta)$ 는 semi-constant 네트워크가 계산해 출력한 Q-value 값을 나타냅니다. 이 정도면, 모두 이해한 것 같습니다! 😊
Hello World!
저는 개인적으로 새로운 개념을 처음 배울 때 가장 좋은 방법은 직접 활용해보는 것이라고 생각합니다. Q-Learning과 Deep Q Networks를 활용해보기 위해 한 가지 게임을 제안드립니다. Agent가 채워야 하는 4칸이 있는 보드판을 떠올려봅시다. Agnet가 비어있는 칸을 선택하면 보상은 $+1$ 을 받고, 그 칸은 채워집니다. 만약 Agent가 비어있지 않은 칸을 선택하면 보상은 $-1$ 을 받습니다. 게임은 모든 칸이 전부 채워지면 끝납니다.
Q-Learning과 DQN 두 가지 방법을 모두 활용해서 Agent가 게임을 마스터할 수 있도록 하는 네트워크를 구현해보세요!
제가 했던 과정은 이 곳에서 확인하실 수 있습니다 :)
행운을 빕니다! 그리고, 어려운 것들을 새로 배웠다는 점, 세 번째로 축하합니다! 👏🏼👏🏼👏🏼
강화학습을 스스로 도전해 볼 준비가 되셨나요? 그렇다면 여기, 조금 더 실용적인 팁들을 정리한 다른 포스팅들이 있습니다!