-
Transfer Learning|학습된 모델을 새로운 프로젝트에 적용하기Machine Learning|Deep Learning/Transfer Learning 2019. 5. 28. 02:23
#Transfer Learning#전이학습#CNN#합성곱 신경망#Image Classification#이미지 분류
이 글은 원작자의 허락 하에 번역한 글입니다!
중간 중간 자연스러운 흐름을 위해 의역한 부분들이 있습니다.
원 의미를 왜곡시키지 않도록 노력하였지만, 부족한 부분이 분명 있을거라고 생각합니다.
어떤 지적이나 조언이든 해주신다면 감사히 받고 더 나은 글을 쓰기 위해 노력하겠습니다.
원문은 ↓ 이곳 ↓ 에서 보실 수 있습니다.Transfer learning from pre-trained models
How to solve any image classification problem quickly and easily
towardsdatascience.com
ㅤ ㅤ
이미지 분류 문제를 어떻게 빠르고 쉽게 해결할 수 있을까?
이 글은 이미지 분류 문제에 전이학습(Transfer Learning)을 적용하는 방법에 대해 설명하는 글입니다.
Keras라이브러리의 사전학습모델(pre-trained model)을 사용해서 직접 실습해보는 예제와 함께 구성하였습니다.
딥러닝은 인공지능의 응용 분야에서 핵심 기술로 빠르게 자리를 잡아가고 있습니다 (LeCun et al. 2015). 그동안 딥러닝은 컴퓨터 비전, 자연어 처리, 그리고 음성인식 등의 여러 분야에서 실로 대단한 성과들을 보여주었고, 이에 따라 딥러닝에 대한 관심은 계속해서 높아지고 있습니다.
ㅤ딥러닝이 뛰어난 성과를 보여주는 분야 중 또다른 한 가지는
이미지 분류 image classification입니다 (Rawat & Wang 2017).
이미지 분류 문제의 목적은 특정 이미지들을 주어진 카테고리로 정확하게 분류하는 것입니다. 이미지 분류에서 전통적으로 유명한 문제로는 '고양이 vs. 강아지' 사진 분류 문제가 있습니다. (Dogs vs. Cats Kaggle Competition)
ㅤ한편, 딥러닝 관점에서, 이미지 분류 문제는 전이 학습(Transfer Learning) 으로 접근할 수 있습니다. 사실, 최상위 랭크를 기록하는 몇몇 이미지 분류 결과들은 전이학습을 이용해 만들어낸 결과들이기도 합니다 (Krizhevsky et al. 2012, Simonyan & Zisserman 2014, He et al. 2016).
Pan & Yang (2010) 의 논문에 전이학습에 대해 포괄적인 설명이 있습니다. 필요하다면 그 글도 읽어보시기를 추천합니다.
ㅤ이 포스트는 이미지 분류 문제에 어떻게 전이학습을 적용시킬 수 있는지, 그에 대한 구체적인 방법들을 설명하고, 또한 직접 실습해보는 예제로 구성되어 있습니다. 실습 예제는
Python언어 기반으로 만들어진Keras라이브러리를 이용합니다. 이 실습 예제를 익히면서 함께 따라해 본다면, 어떤 이미지 분류 문제도 빠르고 쉽게 접근해볼 수 있게 될 것입니다!
# Contents
1. 전이학습에 대하여
2. CNN, 합성곱 신경망
3. 사전에 학습된 모델을 내 프로젝트에 맞게 재정의하기
4. 전이학습의 전체 과정
5. Classifier, 분류기
6. 실습 예제
7. 요약
8. 참조
1. 전이학습에 대하여
전이학습은 높은 정확도를 비교적 짧은 시간 내에 달성할 수 있기 때문에 컴퓨터 비전 분야에서 유명한 방법론 중 하나입니다 (Rawat & Wang 2017). 전이학습을 이용하면, 이미 학습한 문제와 다른 문제를 풀 때에도, 밑바닥에서부터 모델을 쌓아올리는 대신에 이미 학습되어있는 패턴들을 활용해서 적용시킬 수 있습니다. 이를 샤르트르 식으로 표현하면
거인의 어깨에 서서(standing on the soulder of giants)학습하는 것이라고 할 수 있겠습니다!ㅤ
컴퓨터 비전에서 말하는 전이학습은 주로 사전학습 된 모델 (pre-trained model) 을 이용하는 것을 뜻합니다. 사전학습 된 모델이란, 내가 풀고자 하는 문제와 비슷하면서 사이즈가 큰 데이터로 이미 학습이 되어 있는 모델입니다. 그런 큰 데이터로 모델을 학습시키는 것은 오랜 시간과 연산량이 필요하므로, 관례적으로는 이미 공개되어있는 모델들을 그저 import해서 사용합니다 (ex. VGG, Inception, MobileNet). 사전 학습 모델들의 ImageNet(Deng et al. 2009) 이미지 분류 대회에 대한 성능은 Canziani et al. (2016) 논문에 전반적으로 정리되어 있으니 궁금하시다면 찾아보시길 권합니다.
ㅤㅤ
ㅤ
2. CNN, 합성곱 신경망
전이학습에 이용되는 몇몇의 사전 학습 모델들은 큰 사이즈의 합성곱 신경망 (Convolutional Neural Networks, CNN) 구조를 가지고 있습니다 (Voulodimos et al. 2018). 일반적으로, CNN은 다양한 컴퓨터 비전 문제에서 뛰어난 성능을 보여주는 것으로 나타났습니다 (Bengio 2009). CNN이 받은 최근 몇 년 간의 뜨거운 관심은 좋은 성능과, 동시에 학습을 쉽게 할 수 있다는 두 가지 메인 요소가 있었기 때문입니다.
ㅤ
일반적인 CNN은 다음 두 가지 파트로 구성되어 있습니다.
-
Convolutional base
합성곱층과 풀링층이 여러겹 쌓여있는 부분입니다. convolutional base의 목표는 이미지로부터 특징을 효과적으로 추출하는 것 (feature extraction) 입니다. 합성곱층과 풀링층에 대한 직관적인 설명을 보시려면 Chollet (2017) 논문을 참고하세요.
ㅤ -
Classifier
주로 완전 연결 계층 (fully connected layer)로 이루어져 있습니다. 완전 연결 계층이란 모든 계층의 뉴런이 이전 층의 출력 노드와 하나도 빠짐없이 모두 연결되어 있는 층을 말합니다. 분류기(Classifier)의 최종 목표는 추출된 특징을 잘 학습해서 이미지를 알맞은 카테고리로 분류하는 것 (image classification) 입니다.
ㅤ
아래 그림은 CNN을 기반으로 하는 모델의 구조를 나타낸 것입니다.
이 그림은 설명을 위해 간소화시켜서 나타낸 것입니다. 실제 모델은 당연히 이것보다 훨씬 복잡하게 이루어져 있습니다!ㅤ

[그림 1] CNN 기반 모델의 구조
ㅤ이러한 딥러닝 모델의 중요한 성격 중 하나는 바로 "계층적인 특징"을 "스스로" 학습한다는 점입니다.
계층적인 특징을 학습한다는 말이 무슨 뜻이냐면, 모델의 첫 번째 층은 "일반적인(general)" 특징을 추출하도록 하는 학습이 이루어지는 반면에, 모델의 마지막 층에 가까워질수록 특정 데이터셋 또는 특정 문제에서만 나타날 수 있는 "구체적인(specific)" 특징을 추출해내도록 하는 고도화된 학습이 이루어진다는 뜻입니다. 따라서 앞단에 있는 계층들은 다른 데이터셋의 이미지들을 학습할 때도 재사용될 수 있지만, 뒷단의 계층들은 새로운 문제를 맞이할 때마다 새로 학습이 필요합니다.
ㅤYosinski et al. (2014) 논문에서는 이러한 딥러닝의 특성에 대해, '만약 첫 번째 계층에서 추출된 특징이 일반적인 특징이고 마지막 층에서 추출된 특징이 구체적인 특징이라면, 네트워크 내의 어딘가에 일반적인 수준에서 구체적인 수준으로 넘어가는 전환점이 분명 존재할 것이다.' 라고 서술하고 있습니다.
ㅤ결론적으로, 우리가 살펴본 CNN 모델의
Convolutional base부분, 그 중에서도 특히 낮은 레벨의 계층(input에 가까운 계층)일수록 일반적인 특징을 추출할 것이고, 그와 반대로Convolutional base의 높은 레벨의 계층(output에 가까운 계층)과Classifier부분은 보다 구체적이고 특유한 특징들을 추출할 것입니다.
ㅤㅤ
ㅤ
3. 사전에 학습된 모델을 내 프로젝트에 맞게 재정의하기
사전 학습된 모델을 이제 나의 프로젝트에 맞게 재정의한다면, 먼저 원래 모델에 있던 classifier를 없애는 것으로 시작합니다. 원래의 classifier는 삭제하고, 내 목적에 맞는 새로운 classifier를 추가합니다. 그 후 마지막으로는 새롭게 만들어진 나의 모델을 다음 세 가지 전략 중 한 가지 방법을 이용해 파인튜닝(fine-tune)을 진행합니다.
ㅤ# 전략 1 : 전체 모델을 새로 학습시키기
이 방법은 사전학습 모델의 구조만 사용하면서, 내 데이터셋에 맞게 전부 새로 학습시키는 방법입니다. 모델을 밑바닥에서부터 새로 학습시키는 것이므로, 큰 사이즈의 데이터셋이 필요합니다. (그리고, 좋은 컴퓨팅 연산 능력도요!)
ㅤ# 전략 2 : Convolutional base의 일부분은 고정시킨 상태로, 나머지 계층과 classifier를 새로 학습시키기
앞서 언급했듯이, 낮은 레벨의 계층은 일반적인 특징(어떤 문제를 푸느냐에 상관 없이 독립적인 특징)을 추출하고, 높은 레벨의 계층은 구체적이고 특유한 특징(문제에 따라 달라지는 특징)을 추출합니다. 이런 특성을 이용해서, 우리는 신경망의 파라미터 중 어느 정도까지를 재학습시킬지를 정할 수 있습니다.
주로, 만약 데이터셋이 작고 모델의 파라미터가 많다면, 오버피팅이 될 위험이 있으므로 더 많은 계층을 건들지 않고 그대로 둡니다. 반면에, 데이터셋이 크고 그에 비해 모델이 작아서 파라미터가 적다면, 오버피팅에 대한 걱정을 할 필요가 없으므로 더 많은 계층을 학습시켜서 내 프로젝트에 더 적합한 모델로 발전시킬 수 있습니다.
ㅤ# 전략 3 : Convloutional base는 고정시키고, classifier만 새로 학습시키기
이 경우는 보다 극단적인 상황일 때 생각할 수 있는 케이스입니다. convolutional base는 건들지 않고 그대로 두면서 특징 추출 메커니즘으로써 활용하고, classifier만 재학습시키는 방법을 씁니다. 이 방법은 컴퓨팅 연산 능력이 부족하거나 데이터셋이 너무 작을때, 그리고/또는 내가 풀고자 하는 문제가 사전학습모델이 이미 학습한 데이터셋과 매우 비슷할 때 고려해볼 수 있습니다.
ㅤ ㅤ
ㅤ다음은 위에서 설명한 세 가지 전략을 그림으로 나타낸 것입니다.
ㅤ
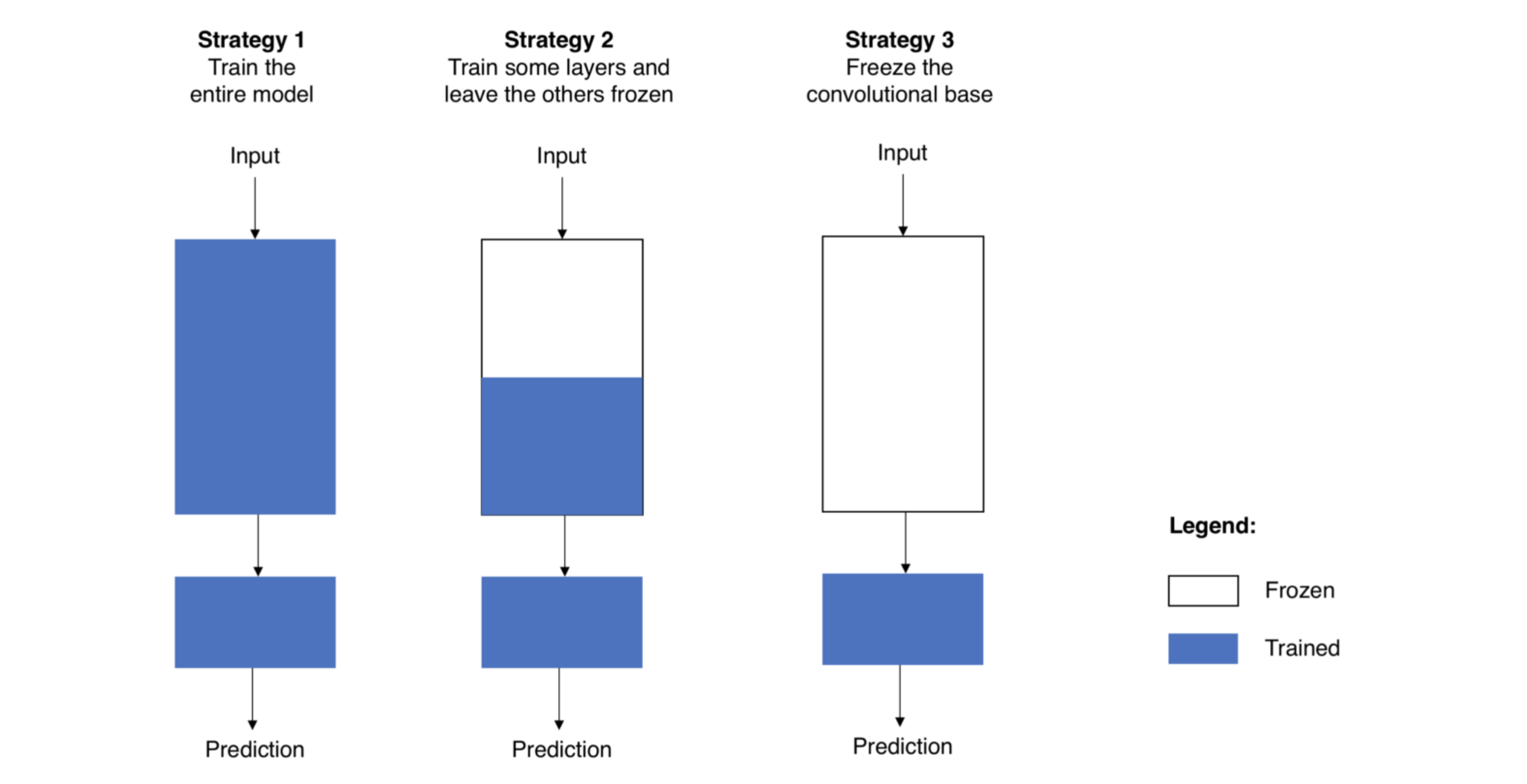
[그림 2] Fine-tuning의 세 가지 전략
ㅤ비교적 간단히 사용할 수 있는 세 번째 전략과 다르게, 첫 번째와 두 번째 전략은 learning rate에 대해서 조심해야 할 필요가 있습니다. learning rate는 신경망에서 파라미터를 얼마나 재조정할 것인지를 결정하는 하이퍼 파라미터입니다. CNN 베이스의 사전학습 모델을 사용할 때에는, 이전에 학습한 내용들을 모두 잊어버릴 위험이 있기 때문에 작은 learning rate를 사용하는 것이 바람직합니다. 사전학습 모델이 잘 학습되었다는 가정하에, 작은 learning rate으로 학습을 시킨다면 CNN 모델의 파라미터들을 너무 빠르게, 혹은 너무 많이 왜곡시키지 않고 원래 학습되어있던 지식을 잘 보존하면서 추가로 학습을 해 나갈 것입니다.
ㅤㅤ
ㅤ
4. 전이학습의 전체 과정
실습을 하기 전에 전이학습의 전체 과정을 요약해본다면 다음과 같습니다.
ㅤ1) 사전학습 모델 선택하기
다양하게 공개되어 있는 사전학습 모델 중에서, 내 문제를 푸는 것에 적합해보이는 모델을 선택합니다. 만약
Keras를 이용한다면, 간단하게 바로 여러가지 사전학습 모델을 사용할 수 있습니다. 대표적인 사전학습 모델로는 VGG (Simonyan & Zisserman 2014), Inception (Szegedy et al. 2015), 그리고 ResNet5 (He et al. 2015) 등이 있습니다. 여기를 보시면 Keras가 제공하는 모든 모델을 확인할 수 있습니다.
ㅤ2) 내 문제가
데이터크기-유사성 그래프에서 어떤 부분에 속하는지 알아보기[그림 3]은 데이터 크기와 데이터 간의 유사성을 기반으로 네 가지 상황을 구분합니다. 이 그래프가 제시하는 네 가지 상황에 따라 내가 속한 상황은 무엇인지 알아보고, 어떤 전략을 써야 하는지를 결정할 수 있습니다. 여기서 작은 데이터셋의 크기는 경험적으로 1000개 이하의 이미지 데이터셋 정도를 말합니다. 데이터셋의 유사성에 대해서는 상식의 선에서 생각해볼 수 있습니다. 예를 들어, 고양이와 강아지를 분류해야 하는 상황이라면, ImageNet 모델은 이미 고양이와 강아지에 대해 학습했기 때문에 내 문제와 유사하다고 할 수 있지만, 암세포를 구분해야 하는 상황이라면, ImageNet은 유사한 데이터셋을 학습한 모델이라고 볼 수 없을 것입니다.
ㅤ3) 내 모델을 Fine-tuning 하기
위에서 데이터 크기와 유사성을 고려해서 내가 어떤 상황에 속하는지 알아보았다면, 이제 각 상황에 따라 구체적으로 어떻게 Fine-tuning을 진행해야 하는지 결정합니다. [그림 4]는 앞서 알아본 사전학습 모델을 재정의하는 세 가지 전략을 각각 어떤 상황에 적용시켜야 하는지 보여줍니다. 다음은 각 상황에 대한 세부 설명입니다.
-
Quadrant 1: 크기가 크고 유사성이 작은 데이터셋일 때
이 경우에는 [전략 1]이 적합합니다. 데이터셋의 크기가 크므로, 모델을 다시 처음부터 내가 원하는 대로 완전히 다시 학습시킬 수 있습니다. 비록 유사성이 거의 없는 데이터로 새로 학습을 시켜야 한다고 해도, 사전 학습 모델의 구조와 파라미터들을 가지고 시작하는 것은 아예 처음 시작하는 것보다 유용할 것입니다.
ㅤ -
Quadrant 2: 크기가 크고 유사성도 높은 데이터셋일 때
Here you are in la-la land. 라라랜드입니다! 어떤 옵션을 선택해도 괜찮은 상황입니다. 그 중에서도, 가장 효과적인 옵션은 [전략 2]로 생각됩니다. 데이터셋의 크기가 커서 오버피팅은 문제가 안 될 것이므로, 우리가 원하는 만큼 학습을 시켜도 됩니다. 하지만, 데이터셋이 유사하다는 이점이 있으므로 모델이 이전에 학습한 지식을 활용하지 않을 이유가 없습니다. 따라서, classifier와 convolutional base의 높은 레벨 계층(뒷단의 계층) 일부만 학습시켜도 충분할 것입니다.
ㅤ -
Quadrant 3: 크기가 작고 유사성도 작은 데이터셋일 때
가장 좋지 않은 상황입니다. 상황을 바꿔보는 게 가장 좋은 옵션일테지만 불가능하다면, 시도해 볼 수 있는 건 [전략 2]뿐입니다. 하지만 convolutoinal base의 계층 중 몇 개의 계층을 학습시키고 몇 개를 얼려야(그대로 두어야) 하는지를 알아내는 것은 어렵습니다. 너무 많은 계층을 새로 학습시키면 작은 데이터셋에 모델이 과적합될 우려가 있고, 너무 적은 계층만을 학습시키면 모델은 제대로 학습되지 않을 것입니다. 아마,Quadrant 2의 상황에서보다는 조금 더 깊은 계층까지 새로 학습을 시킬 필요가 있을 겁니다. 또한, 작은 크기의 데이터셋을 보완하기 위해서data augmentation(데이터를 왜곡 또는 변형시켜서 데이터셋의 크기를 증가시키는 것)과 같은 테크닉에 대해 알아보야 할 것입니다. (data augmentation 기술에 대해 설명해놓은 좋은 자료는 여기에서 확인하실 수 있습니다.)
ㅤ -
Quadrant 4: 크기가 작지만 유사성은 높은 데이터셋일 때
이 상황에서는 [전략 3]이 최선의 선택일 것입니다. 이 경우에는 사전학습모델의 마지막 부분, classifier만 삭제하고 기존의 convolutional base는 특징 추출기로써 사용하고, 추출된 특징을 새 classifier에 넣어서 분류할 수 있도록 학습시키면 됩니다. 즉, 우리가 해야 할 일은 새 classifier만 학습시키는 것입니다! ㅤ
ㅤ

[그림 3] 데이터크기-유사성 그래프ㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤ ㅤㅤㅤㅤ[그림 4] 각 상황에 따른 Fine-tuning 방법
ㅤㅤ
ㅤ
5. Classifier, 분류기
이전에 설명했듯이, CNN기반의 신경망으로 사전 학습된 이미지 분류를 위한 모델은 일반적으로 다음 두 부분으로 구성됩니다.
Convolutional base: 이미지로부터 특징을 추출하는 부분Classifier: 추출된 특징을 입력받아서 최종적으로 이미지의 카테고리를 결정하는 부분
ㅤ
이번에는 classifier, 즉 분류기 부분을 집중적으로 알아보겠습니다. 분류기로써 활용해볼 수 있는 방법 중 대표적인 것 세 가지는 다음과 같습니다.
ㅤ1) Fully-connected layers, 완전 연결 계층
이미지 분류 문제에서 표준으로 쓰이는 방법 중 하나는 완전 연결 계층을 쌓은 후 마지막에 소프트맥스 활성화함수(softmax activated layer) 계층을 놓는 것입니다 (Krizhevsky et al. 2012, Simonyan & Zisserman 2014, Zeiler & Ferhus 2014). 소프트맥스 계층은 주어진 카테고리 각각에 대해 그 카테고리일 확률값을 출력합니다. 따라서 우리는 이미지의 카테고리를 예측할 때 모든 카테고리 중 가장 높은 확률값을 가지는 카테고리를 선택하기만 하면 됩니다.
ㅤ2) Global average pooling, 평균 풀링
조금 다른 관점에서 접근하는 방법으로, 평균 풀링이 있습니다. 이 방법은 Lin et al. 2013 논문에서 제안된 방법으로, convolutional base의 끝에 바로 전에 설명한 Fully-connected layer 대신에 평균 풀링계층을 추가하고, 그 결과값을 바로 소프트맥스 계층과 연결하는 방식입니다. Lin et al. 2013 논문은 이 방법에 대한 더 구체적인 설명과 장점, 단점을 설명하므로 궁금하시다면 확인해보세요!
ㅤ
3) Linear support vector machines, 선형 서포트 벡터 머신
선형 서포트 벡터 머신(SVM)은 또 다른 아이디어의 방법입니다. Tang(2013)의 논문에 따르면, convolutional base에서 추출된 특징을 선형 SVM 분류기로 분류함으로써 정확도를 더 높일 수 있다고 합니다. SVM에 대한 더 자세한 내용은 논문을 참고하시길 바랍니다.
ㅤ ㅤㅤ
ㅤ
6. 실습 예제
이번 실습에서, 우리는 이 세 가지 classifier들이 각각 어떤 식으로 전이학습에 적용될 수 있는지 알아보려고 합니다. Rawat and Wang (2017) 논문에서, 'CNN 구조 끝에서 학습되는 여러가지 classifier들의 성능을 비교해보는 것은 많은 탐구가 필요한 작업이기 때문에 흥미로운 연구 방향을 제시한다.' 라고 언급한 바 있습니다. 각각의 classifier를 기본적인 이미지 데이터셋으로 학습시켜보고 성능을 확인해보면서 얼마나 흥미로운 결과를 보여주는지 직접 확인해보도록 하겠습니다.
ㅤ전체 코드는 여기에서 확인할 수 있습니다.
ㅤ6.1 데이터 준비하기
이번 실습에서는, 우리는 원래의 데이터셋보다 조금 작은 버전을 활용하겠습니다. 이는 제한된 컴퓨팅 연산 능력을 가진 사람(저처럼요!) 들에게 모델 학습이 더 빠르게 이루어질 수 있도록 할 것입니다.
ㅤ작은 버전의 데이터셋을 만들기 위해, 우리는 Chollet (2017) 논문의 코드를 사용하겠습니다.
ㅤ# Create smaller dataset for Dogs vs. Cats import os, shutil original_dataset_dir = '/Users/macbook/dogs_cats_dataset/train/' base_dir = '/Users/macbook/book/dogs_cats/data' if not os.path.exists(base_dir): os.mkdir(base_dir) # Create directories train_dir = os.path.join(base_dir,'train') if not os.path.exists(train_dir): os.mkdir(train_dir) validation_dir = os.path.join(base_dir,'validation') if not os.path.exists(validation_dir): os.mkdir(validation_dir) test_dir = os.path.join(base_dir,'test') if not os.path.exists(test_dir): os.mkdir(test_dir) train_cats_dir = os.path.join(train_dir,'cats') if not os.path.exists(train_cats_dir): os.mkdir(train_cats_dir) train_dogs_dir = os.path.join(train_dir,'dogs') if not os.path.exists(train_dogs_dir): os.mkdir(train_dogs_dir) validation_cats_dir = os.path.join(validation_dir,'cats') if not os.path.exists(validation_cats_dir): os.mkdir(validation_cats_dir) validation_dogs_dir = os.path.join(validation_dir, 'dogs') if not os.path.exists(validation_dogs_dir): os.mkdir(validation_dogs_dir) test_cats_dir = os.path.join(test_dir, 'cats') if not os.path.exists(test_cats_dir): os.mkdir(test_cats_dir) test_dogs_dir = os.path.join(test_dir, 'dogs') if not os.path.exists(test_dogs_dir): os.mkdir(test_dogs_dir) # Copy first 1000 cat images to train_cats_dir fnames = ['cat.{}.jpg'.format(i) for i in range(100)] for fname in fnames: src = os.path.join(original_dataset_dir, fname) dst = os.path.join(train_cats_dir, fname) shutil.copyfile(src, dst) # Copy next 500 cat images to validation_cats_dir fnames = ['cat.{}.jpg'.format(i) for i in range(200, 250)] for fname in fnames: src = os.path.join(original_dataset_dir, fname) dst = os.path.join(validation_cats_dir, fname) shutil.copyfile(src, dst) # Copy next 500 cat images to test_cats_dir fnames = ['cat.{}.jpg'.format(i) for i in range(250,300)] for fname in fnames: src = os.path.join(original_dataset_dir, fname) dst = os.path.join(test_cats_dir, fname) shutil.copyfile(src, dst) # Copy first 1000 dog images to train_dogs_dir fnames = ['dog.{}.jpg'.format(i) for i in range(100)] for fname in fnames: src = os.path.join(original_dataset_dir, fname) dst = os.path.join(train_dogs_dir, fname) shutil.copyfile(src, dst) # Copy next 500 dog images to validation_dogs_dir fnames = ['dog.{}.jpg'.format(i) for i in range(200,250)] for fname in fnames: src = os.path.join(original_dataset_dir, fname) dst = os.path.join(validation_dogs_dir, fname) shutil.copyfile(src, dst) # Copy next 500 dog images to test_dogs_dir fnames = ['dog.{}.jpg'.format(i) for i in range(250,300)] for fname in fnames: src = os.path.join(original_dataset_dir, fname) dst = os.path.join(test_dogs_dir, fname) shutil.copyfile(src, dst) # Sanity checks print('total training cat images:', len(os.listdir(train_cats_dir))) print('total training dog images:', len(os.listdir(train_dogs_dir))) print('total validation cat images:', len(os.listdir(validation_cats_dir))) print('total validation dog images:', len(os.listdir(validation_dogs_dir))) print('total test cat images:', len(os.listdir(test_cats_dir))) print('total test dog images:', len(os.listdir(test_dogs_dir)))[code 1] Dogs vs. Cats 데이터셋의 작은 버전 생성 (raw code)
ㅤㅤ
6.2 convolutional base에서 특징 추출하기
convolutional base는 특징을 추출하는 용도로 사용합니다. 이 특징벡터들은 우리가 원하는 classifier에 입력값으로 들어가서 개인지 고양이인지를 분류하게 될 것입니다.
ㅤ다시 한 번 Chollet (2017) 논문의 코드를 사용합니다.
ㅤ# Extract features import os, shutil from keras.preprocessing.image import ImageDataGenerator datagen = ImageDataGenerator(rescale=1./255) batch_size = 32 def extract_features(directory, sample_count): features = np.zeros(shape=(sample_count, 7, 7, 512)) # Must be equal to the output of the convolutional base labels = np.zeros(shape=(sample_count)) # Preprocess data generator = datagen.flow_from_directory(directory, target_size=(img_width,img_height), batch_size = batch_size, class_mode='binary') # Pass data through convolutional base i = 0 for inputs_batch, labels_batch in generator: features_batch = conv_base.predict(inputs_batch) features[i * batch_size: (i + 1) * batch_size] = features_batch labels[i * batch_size: (i + 1) * batch_size] = labels_batch i += 1 if i * batch_size >= sample_count: break return features, labels train_features, train_labels = extract_features(train_dir, train_size) # Agree with our small dataset size validation_features, validation_labels = extract_features(validation_dir, validation_size) test_features, test_labels = extract_features(test_dir, test_size)
[code 2] convolutional base에서 특징 추출 (raw code)
ㅤㅤ
6.3 세 가지 Classifiers
6.3.1 Fully-connected layers, 완전 연결 계층
첫 번째 방법으로 사용할 분류기는 완전 연결 계층입니다. 이 분류기는 완전 연결 계층들을 쌓아서 만든 형태로, convolutional base에서 추출된 특징 벡터를 입력받습니다.
ㅤ간단하고 빠르게 실행시키기 위해서, Chollet (2018)에서 제안한 조금 수정된 방법을 사용하겠습니다. 특히, 최적화는 RMSProp 대신 Adam을 사용하겠습니다. (Stanford가 그렇게 말했기 때문이죠..!)
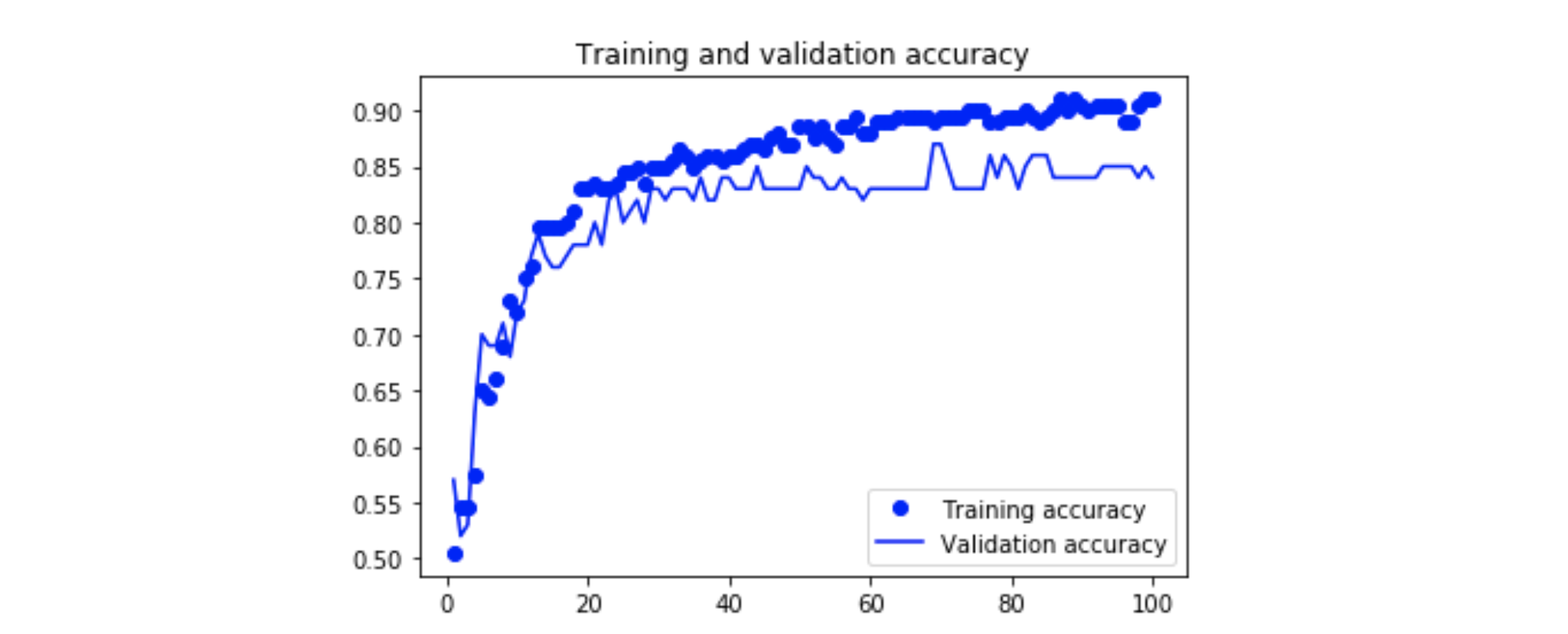
ㅤ[code 3]은 학습하는 코드를, [그림 5]와 [그림 6]은 학습 과정을 보여줍니다.
ㅤ# Define model from keras import models from keras import layers from keras import optimizers epochs = 100 model = models.Sequential() model.add(layers.Flatten(input_shape=(7,7,512))) model.add(layers.Dense(256, activation='relu', input_dim=(7*7*512))) model.add(layers.Dropout(0.5)) model.add(layers.Dense(1, activation='sigmoid')) model.summary() # Compile model model.compile(optimizer=optimizers.Adam(), loss='binary_crossentropy', metrics=['acc']) # Train model history = model.fit(train_features, train_labels, epochs=epochs, batch_size=batch_size, validation_data=(validation_features, validation_labels))
[code 3] 완전연결계층 모델 생성 (raw code)
ㅤㅤ

[그림 5] 완전연결계층 모델의 정확도ㅤ
ㅤ

[그림 6] 완전연결계층 모델의 손실함수값
ㅤㅤ
결과에 대한 짧은 고찰:
-
검증 데이터셋에 대한 정확도는 약 0.85로, 작은 데이터셋을 생각했을 때 나쁘지 않은 결과로 보입니다.
-
모델은 분명 과적합이 되었습니다. 학습 데이터에 대한 성능과 검증 데이터에 대한 성능에 큰 차이가 있습니다.
-
우리는 모델 학습 과정에서 이미 dropout(드롭아웃)을 했으므로, 성능을 더 높이기 위해서는 더 큰 사이즈의 데이터셋을 사용해야 할 것으로 보입니다.
ㅤ
ㅤ
ㅤ
6.3.2 Global average pooling, 평균 풀링
앞서 실행해본 모델과 다른 점은, convolutional base에서 추출된 특징을 완전연결계층에 넣는 대신, 평균 풀링 계층에 넣은 후 시그모이드 활성화 함수에 넣는 것입니다.
ㅤ소프트맥스 함수 대신 시그모이드 함수를 사용하는 것을 주목하세요! 이는 Lin et al. (2013) 논문에서 제안된 방법입니다.
Keras에서 카테고리가 두개인 분류(이진분류)를 하기 위해서는 활성화 함수로 시그모이드 함수를, 손실함수로는 이진 크로스엔트로피 (binary_crossentropy)를 사용해야 합니다 (Chollet 2017). 따라서, Lin et al. (2013) 논문의 코드를 살짝 수정해서 사용하겠습니다.
ㅤ[code 4]는 분류기를 만들고 학습시키는 코드를 보여줍니다. [그림 7]과 [그림 8]은 그에 대한 학습 과정입니다.
ㅤ# Define model from keras import models from keras import layers from keras import optimizers epochs = 100 model = models.Sequential() model.add(layers.GlobalAveragePooling2D(input_shape=(7,7,512))) model.add(layers.Dense(1, activation='sigmoid')) model.summary() # Compile model model.compile(optimizer=optimizers.Adam(), loss='binary_crossentropy', metrics=['acc']) # Train model history = model.fit(train_features, train_labels, epochs=epochs, batch_size=batch_size, validation_data=(validation_features, validation_labels))
[code 4] 평균 풀링 모델 생성 (raw code)
ㅤㅤ
ㅤ
[그림 7] 평균 풀링 모델의 정확도
ㅤㅤ
ㅤ

[그림 8] 평균 풀링 모델의 손실함수값
ㅤㅤ
결과에 대한 짧은 고찰:
-
검증 데이터에 대한 정확도는 앞서 살펴본 완전연결계층 모델과 비슷합니다.
-
이번 모델은 이전 모델만큼 과적합되지 않았습니다!
-
손실함수값은 그래프에 보이는 부분의 마지막까지 계속 줄어들고 있습니다. 아마 epoch 수를 늘리면 모델이 계속 더 학습할 수 있을 것으로 보입니다.
ㅤ
ㅤ
ㅤ
6.3.3 Linear support vector machines, 선형 서포트 벡터 머신
이번 경우에는, 선형 서포트 벡터 머신을 학습시켜 보겠습니다.
ㅤ이번 모델은 머신러닝 모델이므로, 학습을 위해서 머신러닝의 전통적인 방법 사용하겠습니다. K-fold cross-validation 방법을 이용해서 모델을 평가할 것입니다. 따라서 훈련 데이터셋과 검증 데이터셋을 하나로 합쳐서 사용하겠습니다. 테스트 데이터는 여전히 분리시켜 놓습니다! ㅤ
# Concatenate training and validation sets svm_features = np.concatenate((train_features, validation_features)) svm_labels = np.concatenate((train_labels, validation_labels))
[code 5] 데이터 합치기 (raw code)
ㅤ여기서 잠깐, 우리는 SVM 모델은 단 하나의 파라미터만 갖는다는 사실을 기억합시다! 바로 에러율에 대한 규제 파라미터
C입니다. 이 파라미터를 최적화하기 위해서, 그리드 서치(Grid-Search) 방법을 사용하겠습니다. [code 6]은 모델 생성에 대한 코드를, [그림 9]는 학습 과정을 보여줍니다.
ㅤ# Build model import sklearn from sklearn.cross_validation import train_test_split from sklearn.grid_search import GridSearchCV from sklearn.svm import LinearSVC X_train, y_train = svm_features.reshape(300,7*7*512), svm_labels param = [{ "C": [0.01, 0.1, 1, 10, 100] }] svm = LinearSVC(penalty='l2', loss='squared_hinge') # As in Tang (2013) clf = GridSearchCV(svm, param, cv=10) clf.fit(X_train, y_train)
[code 6] SVM 모델 생성 (raw code)
ㅤ ㅤ
[그림 9] SVM 모델의 정확도
ㅤㅤ
ㅤ
결과에 대한 짧은 고찰:
-
모델의 정확도는 약 0.86으로, 이전의 모델들과 비슷합니다.
-
모델은 거의 과적합이 되었습니다. 과적합이 되지 않고서야 학습 데이터에 대한 정확도가 항상 1.0이 나오지 않으니까요!
-
모델의 정확도는 일반적으로 훈련 데이터 샘플의 수가 늘어남에 따라 커져야 합니다. 하지만, 그래프에는 이러한 양상이 나타나지 않습니다. 이는 아마 과적합이 되었기 때문일 것입니다. 데이터셋을 더 늘렸을 때 모델이 어떻게 반응하는지를 확인해볼 필요가 있을 것 같습니다.
ㅤ
ㅤ
ㅤ
7. 요약
이번 포스트에서, 우리는 다음과 같은 것들을 공부하였습니다.
- 전이학습, 합성곱 신경망, 그리고 사전학습 모델에 대한 개념
- 모델을 재정의하기 위한 fine-tuning의 전략 세 가지
- 데이터의 크기와 유사성에 기반하여 fine-tuning의 전략을 선택하는 방법
- convolutional base에서 추출된 특징을 입력받을 수 있는 분류기의 세 가지 종류
- 각 분류기를 처음부터 끝까지 직접 학습시켜보는 예제
ㅤ
이 글을 읽고 딥러닝 프로젝트를 시작해보고 싶은 동기가 생기셨기를 바랍니다. 이 분야는 완전히 새로운 것들을 매일 발견할 수 있는 굉장히 흥미로운 분야입니다!또한, 이 글을 읽는 모든 분께 조금의 도움이라도 되었기를 바랍니다. 질문이나 제안 등 어떤 의견이라도 있으시다면 편하게 말씀해주세요! 감사합니다.
ㅤ ㅤㅤ
ㅤ
ㅤ
8. 참조
[1] Bengio, Y., 2009. Learning deep architectures for AI. Foundations and trends in Machine Learning, 2(1), pp.1–127.
[2] Canziani, A., Paszke, A. and Culurciello, E., 2016. An analysis of deep neural network models for practical applications. arXiv preprint arXiv:1605.07678.
[4] Chollet, F., 2017. Deep learning with python. Manning Publications Co..
[5] Deng, J., Dong, W., Socher, R., Li, L.J., Li, K. and Fei-Fei, L., 2009, June. Imagenet: A large-scale hierarchical image database. In Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conference on (pp. 248–255). Ieee.
[6] He, K., Zhang, X., Ren, S. and Sun, J., 2016. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770–778).
[7] Krizhevsky, A., Sutskever, I. and Hinton, G.E., 2012. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems (pp. 1097–1105).
[8] LeCun, Y., Bengio, Y. and Hinton, G., 2015. Deep learning. nature, 521(7553), p.436.
[9] Lin, M., Chen, Q. and Yan, S., 2013. Network in network. arXiv preprint arXiv:1312.4400.
[10] Pan, S.J. and Yang, Q., 2010. A survey on transfer learning. IEEE Transactions on knowledge and data engineering, 22(10), pp.1345–1359.
[11] Rawat, W. and Wang, Z., 2017. Deep convolutional neural networks for image classification: A comprehensive review. Neural computation, 29(9), pp.2352–2449.
[12] Simonyan, K. and Zisserman, A., 2014. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556.
[13] Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J. and Wojna, Z., 2016. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 2818–2826).
[14] Tang, Y., 2013. Deep learning using linear support vector machines. arXiv preprint arXiv:1306.0239.
[15] Voulodimos, A., Doulamis, N., Doulamis, A. and Protopapadakis, E., 2018. Deep learning for computer vision: A brief review. Computational intelligence and neuroscience, 2018.
[16] Yosinski, J., Clune, J., Bengio, Y. and Lipson, H., 2014. How transferable are features in deep neural networks?. In Advances in neural information processing systems (pp. 3320–3328).
[17] Zeiler, M.D. and Fergus, R., 2014, September. Visualizing and understanding convolutional networks. In European conference on computer vision (pp. 818–833). Springer, Cham.
저의 또다른 프로젝트에 대해서는 pmarcelino.com에서 보실 수 있습니다.
또, 제가 쓰는 인간, 기계, 그리고 과학에 대한 새로운 글을 여기에서 구독하실 수 있습니다.
ㅤ댓글
-